The Tech-crew meetup planned during The Gathering 2017 is starting to take shape.
A brief summary of what it is: a social event for people who do tech-related work at computer parties. See the original invite for details.
So far this is what I know:
Time: Friday, 18:00, location disclosed to those who are invited (which is anyone who drop me an e-mail).
I’ve gotten 9 signups, totaling 16+ people, not counting myself or whoever from Tech:Net at TG is available. All together more than 10 different parties are represented, spanning all sizes.
And there’s still room for lots and lots more. So if you volunteer at a computer party or similar event in a technical capacity and want to hangout, drop me an e-mail at kly@gathering.org and I’ll add you to the list (Please let me know what party(or parties) and roughly size, and if it’s just you or if you bring a friend (or friends)).
The agenda is pretty hazy. I figure this is what we do:
-
I say hello I suppose.
-
Go around the room, everyone presents them self and tell us a little bit about what party (or parties) they volunteer for. Nice things to include is size, where you get your stuff from (rent? borrow? steal? “bring your own device”?), what you do for internet, special considerations, or really whatever comes to mind.
-
????
-
????
What I want to avoid is that this becomes a “Tech:Net at The Gathering tells you how to do stuff”-thing. We’re represented, and we’ll obviously talk about whatever, but we’re all there as equal participants. Many of the challenges we have with 5000 participants is irrelevant to most of you, yet smaller parties have challenges and opportunities that are just as interesting to discuss.
If you want to do a small presentation, or want to talk about a specific topic, then let me know and we’ll make room for it.
Topics I might suggest to get things started:
(X) Do you do end-user support? How much/little?
(X) How do you get a deal with an ISP? Do you have someone you can call if the uplink goes down at 2AM?
(X) Do you use subnetting at all? If so: What was the breaking point where it became necessary?
(X) Where do you get equipment from?
(X) Firewalling? Either voluntary or involuntary (e.g.: getting internet through filtered school network)
(X) Public addresses or NAT?
(X) Do you provide IPv6? Do you care? Do you want to?
(X) ?????
We have the room until we’re done basically. and there’ll be some type of food. If there aren’t too many of us, there might be time for a unique guided tour too, but I’m not making any promises (remember: I’m lazy).
Update: We’re now up to 23 “confirmed” signups representing at least 13 different events. And we’ve secured food, courtesy of KANDU.
All your base are belong to us!
We will have a slightly higher access point density this year compared to TG16. While it might make sense on paper to introduce more APs we seem to forget how much work it actually is to prepare them in such large quantities…
Earlier today we unboxed 276(!) base stations/access points and prepared them for for their journey to Vikingskipet, Hamar.
A big thank you to Avantis for lending us their facilities!







The beacons are lit!
We are happy to report that the internet connection for TG17 is up and running.
Tech:Net decided to take the “pre-TG” preparations one step further this year by building our backbone network and installing our DHCP/DNS servers a week before schedule! This gives us the opportunity to tweak and polish all the nuts and bolts of our most critical infrastructure without being on site.
What does this mean for us? It means that we’re able to deploy and provision our edge switches from day 1 without waiting for internet access or the DHCP/DNS-servers to be installed on the first day.
Pretty sweet!

Stay tuned – we will post details about our network design later on..
Do you do Tech-stuff at a computer party? Any computer party? Then this is for you.
We are looking to put together an informal “Tech-meetup” during The Gathering 2017. The exact program is yet to be decided, the only thing we know is who we want there: Anyone who are part of a tech crew at a computer part or similar event.
This is the result of seeing just how many great people there are out there. And to be more open about what we do at The Gathering, or any other computer party.
The idea is simple: We meet up during the event. Most likely some time during Friday (daytime), but that’s subject to change. We perhaps do a small presentation of TG tech crew with a twist of some sort, Q&A, and then open the floor to discussion about whatever. There’s no super-hard agenda. We can talk about TCP checksum mechanics, DHCP lease times, cable termination, how to best store switches, what candy makes for the best NOC-candy, pros and cons of renting equipment versus buying it. Or just exchange “war stories”.
Does this sound interesting? Then drop me a mail at kly@gathering.org and let me know. This isn’t an application, just a “I want in! I’ve been setting up the network at this local party with 40 participants for the last few years and this would be fun!” thing.
I’m sure we should’ve put together a better sign-up process, but we’re lazy.
Well, I’m lazy anyway. If my mail-box explodes due to this, we might have to rethink this.
From “our” side you can expect me and whoever I manage to kidnap. I know several people in the NOC have expressed an interest. We’ll also obviously provide some sort of room.
Hello!
This year, the Info:System has had some major changes. The structure of The Gathering has been changed, and in that process the Info:Systems crew has been renamed Core:Systems (read more about the change here, in Norwegian..). Oh, and another thing, no one from the old Info:Systems crew is participating this year. That means the entire Systems crew is new blood. Of course, this is not without some challenges.
Christian, aka lizter, has been so nice to help with the transition. He has been with the old Info:Systems crew for many years and has a lot of information and experience that we in Core:Systems really appreciate. Together with reading code, understanding documentation and sorting through config files, we have managed to somewhat get control over the potentially messy situation. I mean, everyone with some programming and/or IT-background knows it can be a messy thing to take over the work of a group of people.
We are pretty sure TG17 will be a really nice experience for all of us new bloods, and we really hope that the transition has not been too obvious. Well… Apart from closing down the forum. And did you notice the front page has SSL now? More on that later!
Just wanted to let you all know that The Gathering Tech crew is actually here working.

After working for almost two full days, some tasks require more thought than others.


Our partners is also here, working with us to deliver you the best possible network experience!
http://stats.tg15.gathering.org/
Simplifying and making WiFi less complex and ready to adopt the user needs.
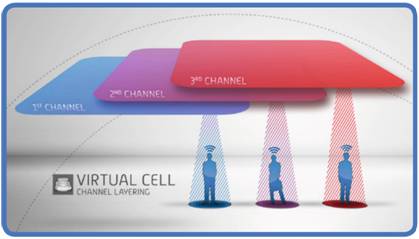
The image below is an example of how channel layers can be deployed to support high client density areas such as a open space like TG. For this we will use different ESSIDs, some deployed on multiple channels some may only be needed on one or two channels. The ESSID used for video broadcasting may be at just one channel. This channel is then “in the air” reserved for this purpose only. Do we need capacity it’s all about adding in AP’s and maybe using more channels for this ESSID.
This can in general actually for TG be handled by just one wireless controller, but for density and RF reasons we can spilt the channels and ESSID we need across multiple controllers also. We have also placed in a redundant controller ready if one of the master controllers should fail.
In addition we use the unique Airtime Fairness technology Meru provides by default.
Meru’s Airtime Fairness governs Wi-Fi access so that every client gets the same amount of time, ensuring consistent performance for the users. With Meru Airtime Fairness(r), the speed of the network is not determined by the slowest traffic. By allocating time equally among clients, Airtime Fairness allows every transmission to move at its highest potential. At TG this is very useful since we will serve many wifi clients in same RF space ☺. So we will most likely use all the possible RF bandwidth, but dived equal to the clients based on air time.
Network Management:
For getting the option to monitor and follow the wireless network at TG we use Meru Network Manager
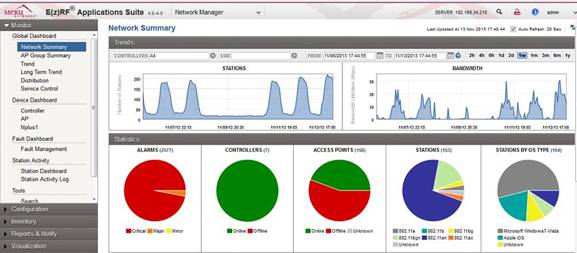
We can then track down clients, usage per AP/radio, controller and so on. This will give a good insight where to fine-tune and optimize the entire installation at TG.
Here is the latest revision of the wireless design, the different colors indicates different layers:
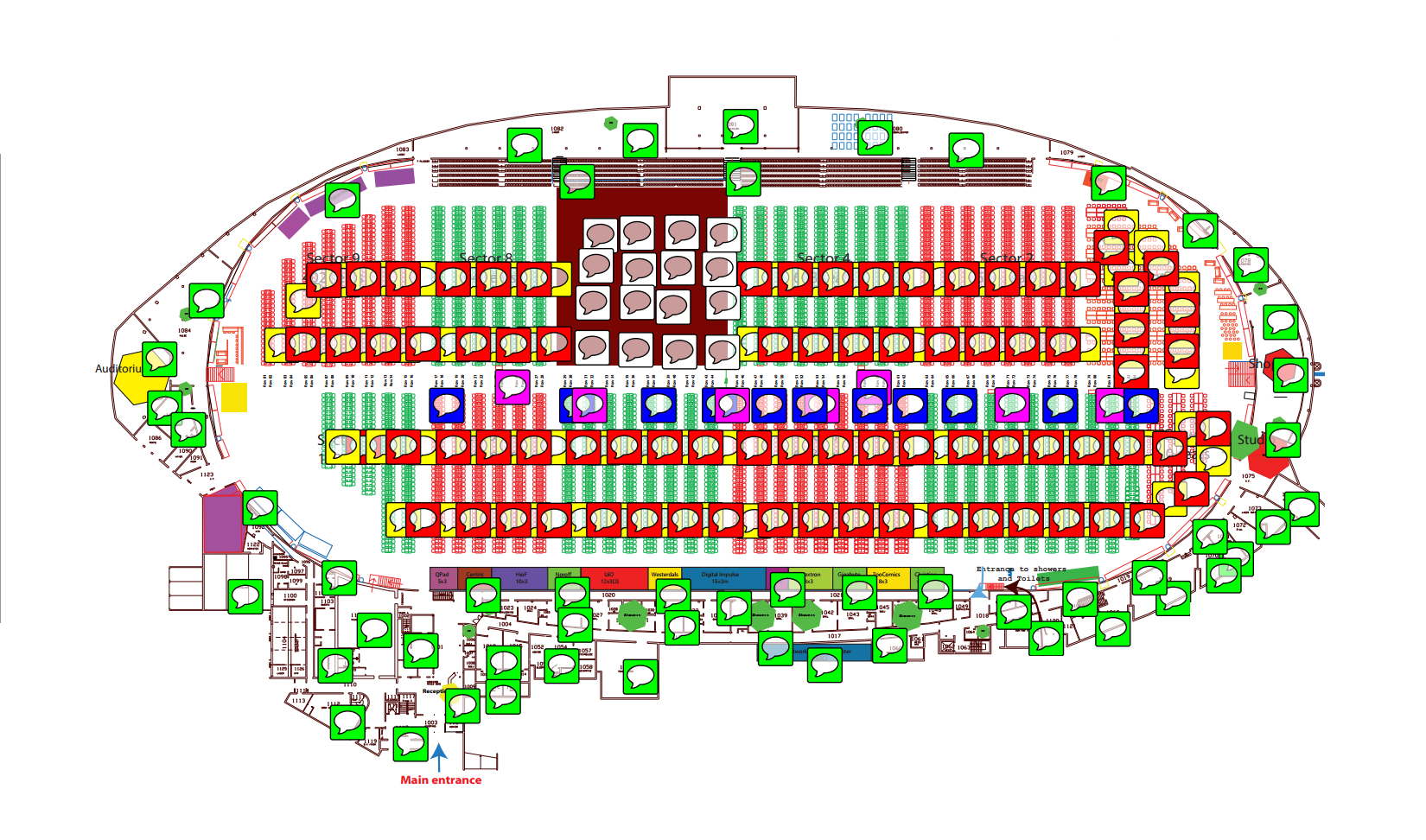
(we will make the final version in high quality format available after TG).
Here are some relevant links to Meru resources, if you are interested in wireless networking:
http://www.merunetworks.com/
http://blog.merunetworks.com/blog/
https://www.youtube.com/user/merunetworks
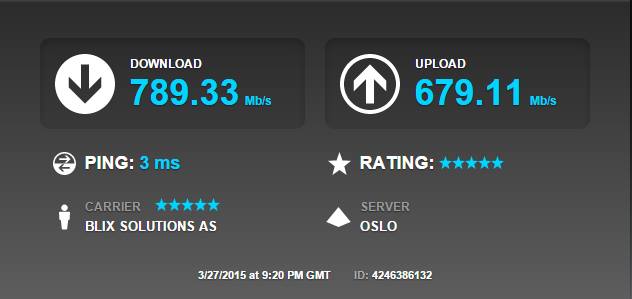
What is this, you might ask?

This is the 10Gig fiber optical transceivers provided by SmartOptics. These transceivers run on different wavelengths and therefore can “talk” over the same pair of fiber from Hamar to Oslo. SmartOptics; awesome people that deliver awesome equipment <3 🙂





