PS: Det er 2. april i dag. Dette er altså ikke en aprilsnarrspøk.
Vi sliter med for mange muggabytes i TP-kablene våre. Kablene har rett og slett blitt mugne under kaldlagring de siste årene.
Av helsemessige årsaker vil ikke de mugne kablene benyttes.
Det pågår nå en heftig koordinering mellom leverandører, Tech-crewet og Logistikk-crewet for å fremskaffe såpass mye kabling. Så får vi se om det blir manuell terminering av plugger, eller om de er ferdigterminert. Mange timer jobb blir det uansett.
Til deg som deltager: Dette er ikke noe å bekymre seg for. Vi håndterer dette, og lager tidenes beste TG \o/
Heia bloggen! Tech:net har holdt på i skipet i rundt ett døgn nå, og vi har fått gjort mye.
Status badstue
Vi har løst varmeproblemene på “tele-rommet”; døra står åpen, og noen av boksene er flyttet ut av rommet. Kjølemaskina på rommet er defekt. Hurra!
Her ser vi r1.tele før vi fikk kontroll på temperaturen:
Status natfw1.tele
Dette clusteret (SRX4600) er flyttet ut av tele-rommet for å få ned varmen i rommet. I tillegg har den ene noden i clusteret dødd, og nLogic og Juniper har skaffet ny boks for den defekte. Takk for fin og problemfri støtte ♥
Status d1.roof
Her har den ene Juniper QFX5120-en dødd. Den skulle stått i et virtual-chassis oppe i taket, og fungere som aggregering for alle distroene på gulvet.
Den fungerte fint da vi preprovisjonerte den på Frivillighetshuset i Oslo, men når den skulle bootes på Hamar så er den jojo under boot. Dette er switcher som kommer fra demodepoet til Juniper, så de kan ha blitt hardt håndtert tidligere.
Juniper og nLogic vil forsøke å få erstattet den før onsdags morgen. Om ikke så blir d1.roof bestående av 2 x QFX5110 istedenfor. Me får sjå.
Sist helg hadde Tech:Net en dag i Vikingskipet hvor vi installerte et par rutere og servere. Vi koblet opp Internett linjen og sjekket at servere og utstyr var nåbare fra utsiden.
Det ble kanskje litt vel mye utstyr inne på det lille rommet, for nå er det godt og varmt der inne 🥵
sjurtf@r1.tele> show chassis environment | match Intake CB 0 Intake OK 48 degrees C / 118 degrees F CB 1 Intake OK 49 degrees C / 120 degrees F FPC 2 Intake OK 49 degrees C / 120 degrees F FPC 3 Intake OK 50 degrees C / 122 degrees F FPC 4 Intake OK 50 degrees C / 122 degrees F FPC 5 Intake OK 51 degrees C / 123 degrees F
Selv om det nå er mulig å steke bacon på MXen som står der så har vi fått brukt uken til å gjøre en del forarbeid.
Fredag som kommer så drar vi til Hamar og opprigget vårt starter for fullt lørdag morgen.
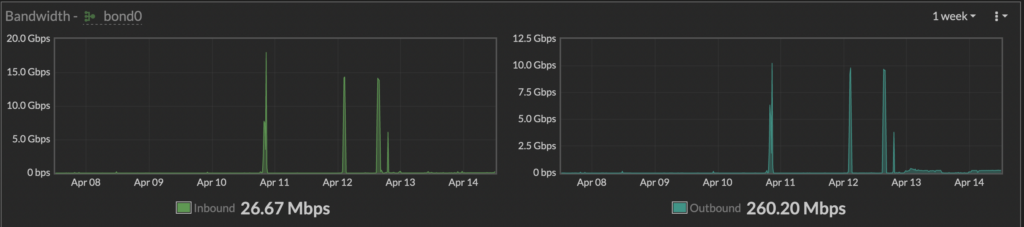
Stats og stream
Gondul (Overvåkingsverktøyet) vårt er nå i drift og den offentlige versjonen er tilgjengelig. Vi har også et weathermap som man kan følge med på.
Nytt av året er selvbetjening av VMer, også til deltakere med plass i skipet.
Med en bruker på Geekevents (eller Wannabe for crew) kan du logge inn og opprette både virtuelle maskiner og ferdig oppsatte spillservere.
Alt av detaljer er ikke klart. Planen er å tilby siste Debian, Ubuntu og Rocky Linux. Mangler vi din favoritt distribusjon? Gi beskjed i vår Discord server
Ferdig installert spill-servere leveres via Pterodactyl.
Presise maskinvarespesifikasjoner er fortsatt under utvikling. Målet vårt er å tilby kraftige nok maskiner til å kjøre de fleste spillservere og annen lab, samtidig som vi ønsker så mange brukere som mulig.
Forrige helg hadde Tech-crewet årets store samling, Tech:Gathering, der det var mye møteaktivitet, sosialisering og ymse. Denne helgen, har Tech:Net samlet seg for en ren arbeidshelg. Utstyret fra Juniper har kommet, den første serveren fra Nextron er i hus og vi begynner å konfe utstyr og teste at det vi vil ha fungerer!
Av ting vi har gjort i helga:
Sette opp core-ruteren
Softwareoppgradere distro-svitsjer, sette basisconfig på dem, teste
Forsøke og feile å få opp Mist Edge i en VM (…)
Confe brannvegger
Gjøre klar ringen til bruk
Teste Multirate
Knote med “nytt” southcam
Teste utrullingsautomatikk
Også har vi tatt sikringen på frivillighetshuset på grunn av overbelastning da.
To ganger.
Men uansett sikringer eller ei, vi er straks klar for “pre-opprigget” – en tur opp til vikingskipet for å sette opp utstyr et par uker før det ordinære opprigget til tg starter.
Etter fler år uten å få bygge et stort nettverk i påskehytta vår, Vikingskipet, så er det endelig snart tid for TG igjen.
Partnere
Vi viderefører det gode samarbeidet med våre venner i nLogic og Juniper Networks, og skal i år, som tidligere bygge kjernen i nettverket på Juniper MX-plattformen. Nytt av året så vil Juniper Networks også levere det trådløse nettverket basert med Juniper Mist. Vi gleder oss veldig til å prøve ut dette og det fortjener sin egen blogpost.
Vi fortsetter med Telenor som ISP og de vil som tidligere år levere oss 50G fordelt på 5x10GbE linker mot Telenor sin ruter i Hamar.
Nextron vil som tidligere stå for server leveransene.
Første dataparty med 10G til deltakere på bordene?
Fler og fler hovedkort og laptoper kommer nå med nettverkskort som har NBASE-T støtte. Det vil si at nettverksporten kan oppnå en linkhastighet på 2.5G, 5G og 10G (som regel i tillegg til 10/100/1000). TG var tidlig ute med gigabit til deltakerene, nå vil vi være tidlig med også høyere hastigheter på bordradene. Vi ønsker å se hvor utbredt dette er i utstyret som tas med på TG, og hvordan etterspørselen på dette er, samt legge tilrette for mer bruk av båndbredde i nettverket vårt. Bruk mer båndbredde!
Juniper Networks har derfor latt oss låne et lite knippe EX4300-48MP svitsjer som støtter 2.5GbE, 5GbE og 10GbE i tillegg til gode gamle 1GbE. Noen av disse kommer vi til å plassere ut på noen deltakerbord, såklart uten ekstra kost for deltakeren. Nøyaktig hvilke rader disse blir plassert på håper vi å kunne si noe om innen det åpnes opp for seating, men plasseringen av disse avhenger av hvordan ting blir plassert fysisk i Vikingskipet.
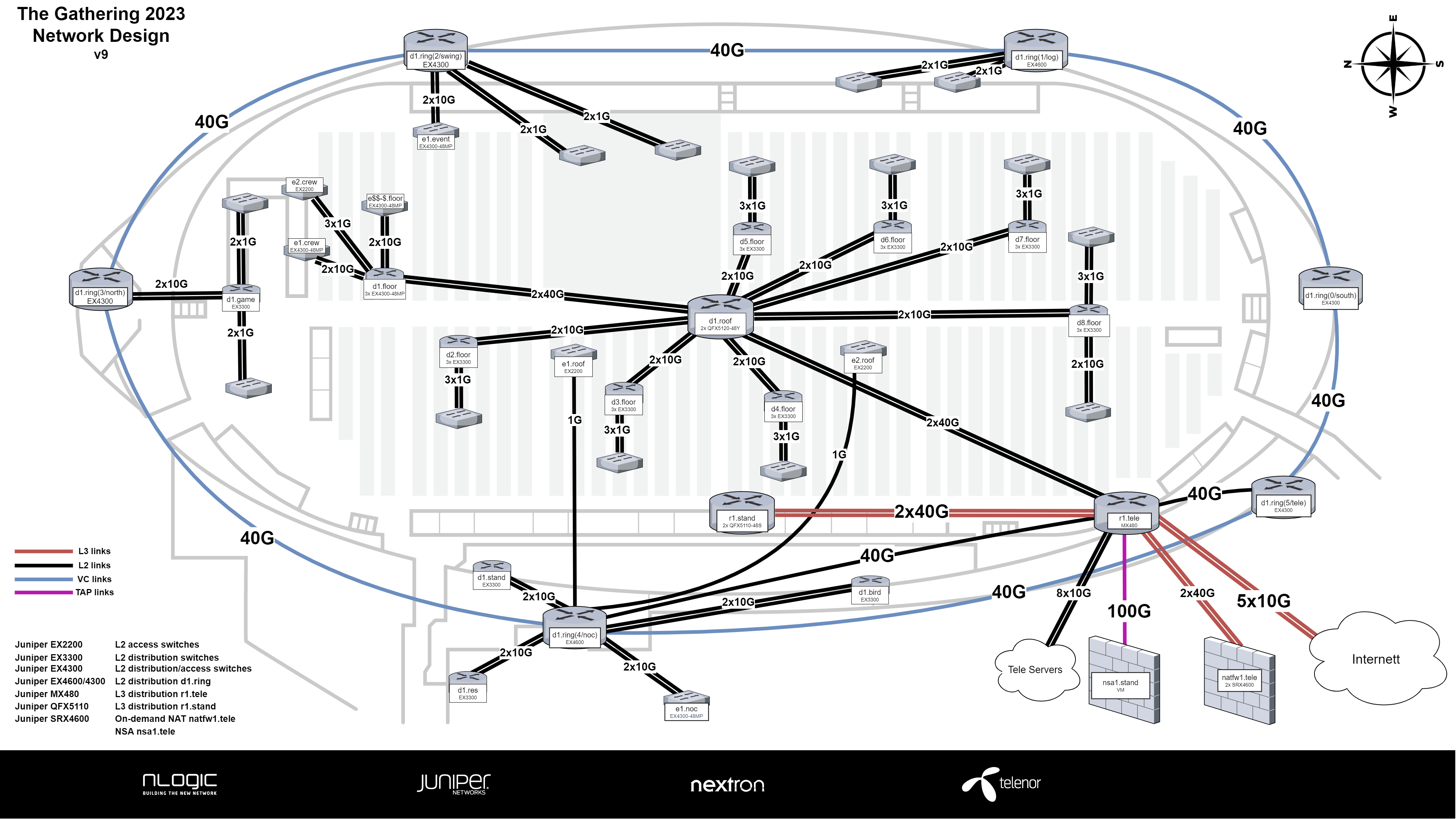
Design
Årets design bygger videre på designet og erfaringer fra TG19, samt planarbeidet vi rakk før TG20 ble avlyst. Justeringer vi har gjort:
Gjøre (omtrent) alt av L3 på MX480 som nå vil stå fysisk plassert på tele (derav nytt navn r1.tele)
Utskutte distribusjonsswitcher fra ringen for å redusere behov for mange lange parallelle kabelstrekk (eksempelvis d1.bird)
Aggregering av uplinkene til distribusjonsswitchene på gulvet med 2 stk QFX5120 i taket (d1.roof) for å redusere fiberstrekk til taket.
Et SRX4600 cluster for å gjøre NAT av ymse og litt eksperimentering.
En av VC-distribusjonsswitchene på gulvet blir basert på EX4300-48MP. Denne skal håndtere uplinkene til tilsvarende switcher på bordene. Denne vil få 2x40G uplink til taket. På tegningen heter denne d1.floor, men det er ikke sikkert den vil stå fysisk der den er tegnet inn.
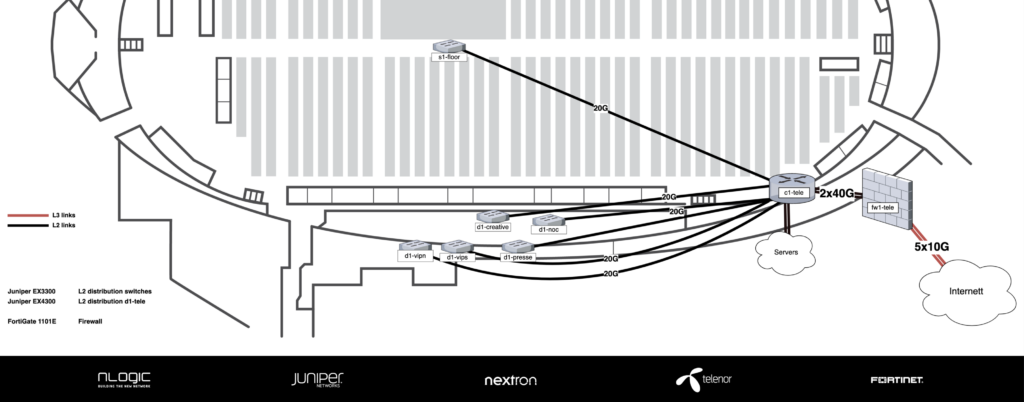
Når vi først fikk muligheten til å sette opp et TG-nettverk i Vikingskipet etter mange år uten, ble det såklart overkill.
Som du ser er det mindre en et vanlig TG. Nesten hele nettverket er bygd på KANDU sitt eget Juniper utstyr (EX2200, EX3300 og EX4300). Unntaket er Fortinet FortiGate 1100E som ble brukt som brannmur.
Fiber patch i NOC. Her går det fiber til TeleNOC (Network Operations Center) som i år er delt med Creative studioPatch på Tele (Fiber fra NOC kommer inn her)
Vi er også så heldig at tidligere TG crew har installert “ringen” i skipet. Det gjør at vi kan patche fiber rundt hele skipet. Som også gjør at vi kan kjøre alt av distribusjon på Tele og bare patche fiber ditt vi trenger det. Core er 4 stk Juniper EX4300 i VC og EX3300 for kant.
c1-tele
Behovet for servere er ikke veldig stort, men vi hadde noen fysiske servere fra Håvard/Casual Gaming. Det ble stort bare brukt til lek og litt lab. DHCP kjørte på FortiGaten og vi hadde en VPN til KANDU/Systemstøtte for litt annet.
Tech er på plass i Vikingskipet og vi har internett!
Litt speedtesting
Vi kommer også til å ha en stream på TGTVCreative hvor vi skal snakke litt om dataparty og hva vi har gjort på årets arrangement. Tune in på Twitch fredag 14:30!
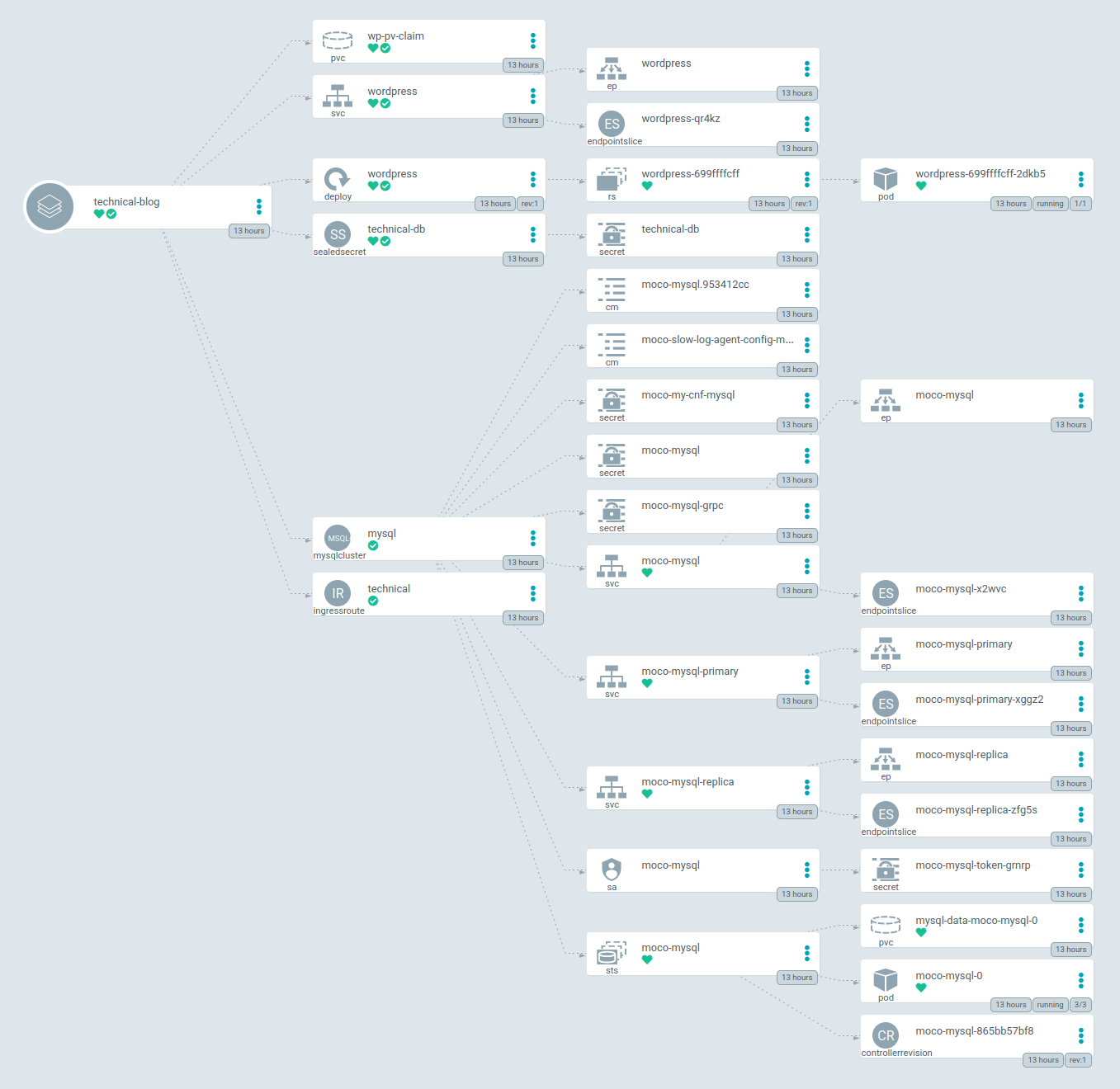
Til dere som har søkt crew til TG22 har nok merket noe nytt med Wannabe. Nettopp! Wannabe kjører i Kubernetes (og vi har darkmode!). Mer om Kubernetes og Wannabe5 må bli en annen bloggpost. Denne korte posten handler om vår blogg.
Med ny versjon av Wannabe ble det klart vi ønsket mer automatisering og DevOps. Denne bloggen ble egentlig planlagt som den første produksjons-workload i det nye clusteret. Men på grunn av litt dårlig planlegging ble Wannabe5 først. Ca 2 måneder etter vi gikk live med Wannabe ble det denne bloggen sin tur.
Vi bruker Argo CD for å få “Infrastructure as Code” og “GitOps”
Bloggen er en ganske liten deployment, kun 1 pod (container) for selve wordpress. Traefik for ingress og MOCO som MySQL Operator.
MOCO er litt av grunnen til vi valgte å flytte Tech-bloggen, både Wannabe og Gathering.org bruker MySQL som database. Vi har et ønske om å bygge de mest kritiske tjenestene våre redudant og et steg på veien er å teste ut MySQL Clustering i Kubernetes.
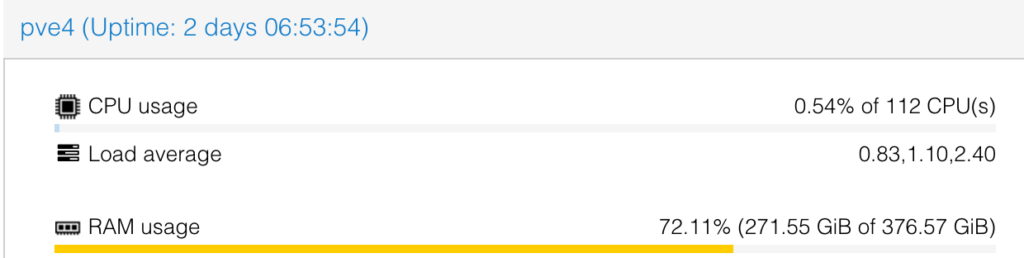
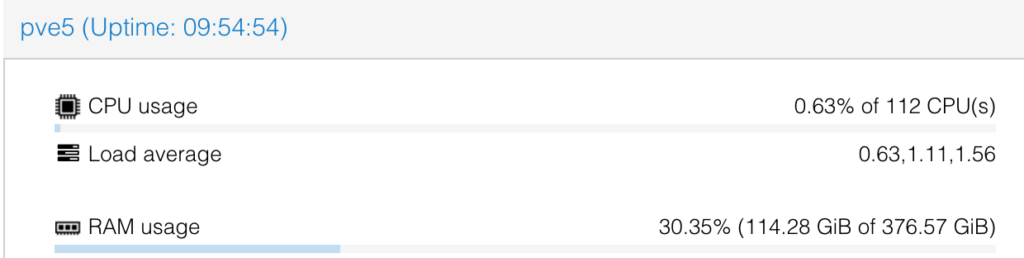
Takk til Nextron for nye servere til vårt driftsmiljø <3
2 nye servere; hver med 384 GB ram og 2 stk Intel Xeon Gold 6258R. Allerede i full sving for TG:Online. Der skal dei blant annet brukes til Minecraft, video streaming og Tech:Online.