La meg introdusere deg til crewet Info:Systemstøtte. Et relativt ukjent navn for mange, men crewet består av det gamle Info/Core:Systems og den tidligere Driftsgruppa.
Vi er et crew som har ansvar for stort og smått, og vi har et behov for søkere for TG25. Vi trenger folk som kan å programmere PHP, Python, Javascript/React eller noe annet spennende. I tillegg trenger vi UX-designere og mennesker som har lyst å jobbe med support.
Arbeidsoppgaver vil være utvikling av nettsider (TG.no), Wannabe (PHP/Laravel) og diverse andre støttesystemer (Python/Django), samt drift av diverse systemer og servere (Proxmox som virtualiseringsmiljø, Fortinet på nettverk og litt Kubernetes).
Høres dette ut som noe som kan være spennende for deg? Send en søknad på wannabe.gathering.org
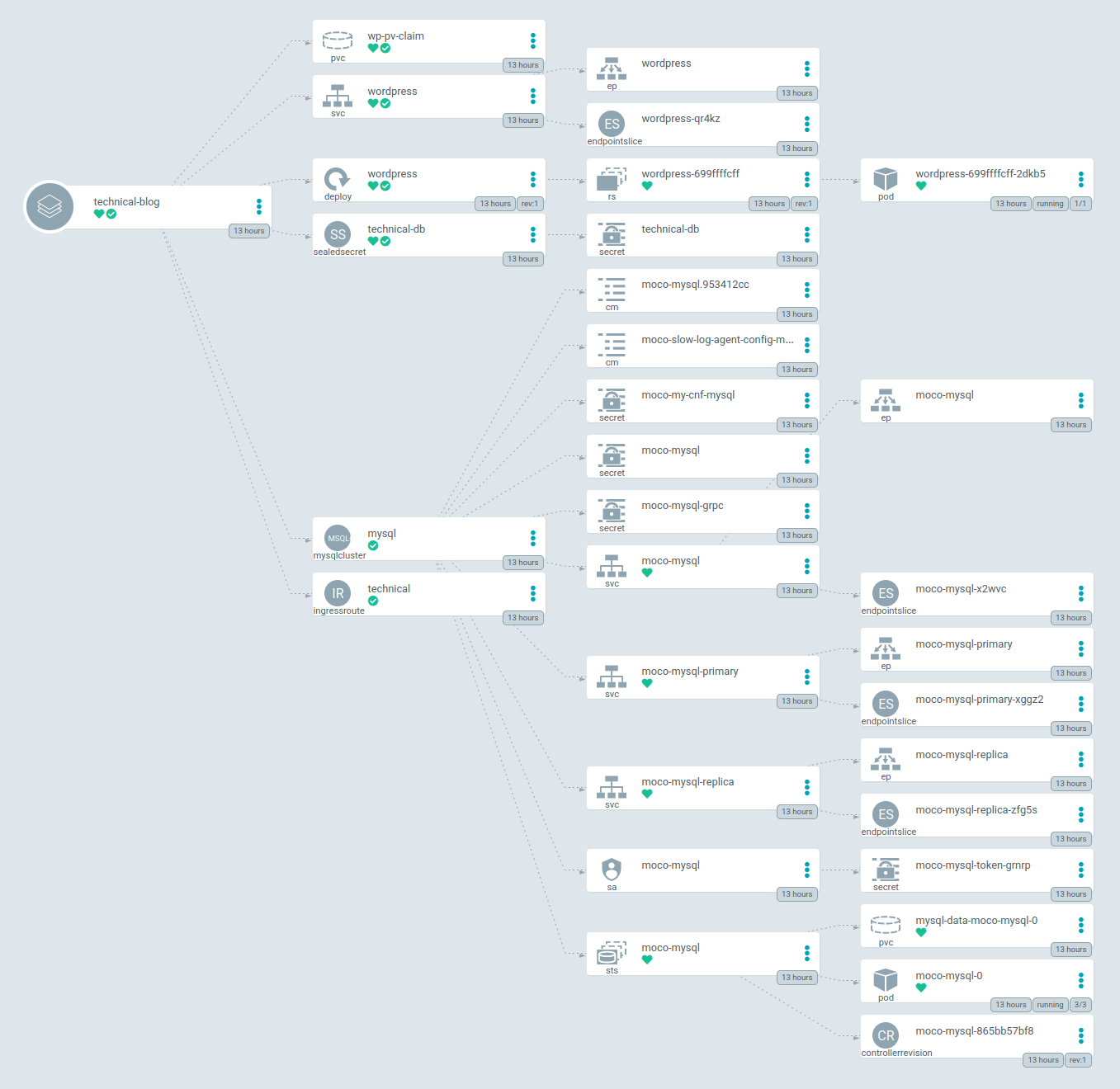
Til dere som har søkt crew til TG22 har nok merket noe nytt med Wannabe. Nettopp! Wannabe kjører i Kubernetes (og vi har darkmode!). Mer om Kubernetes og Wannabe5 må bli en annen bloggpost. Denne korte posten handler om vår blogg.
Med ny versjon av Wannabe ble det klart vi ønsket mer automatisering og DevOps. Denne bloggen ble egentlig planlagt som den første produksjons-workload i det nye clusteret. Men på grunn av litt dårlig planlegging ble Wannabe5 først. Ca 2 måneder etter vi gikk live med Wannabe ble det denne bloggen sin tur.
Vi bruker Argo CD for å få “Infrastructure as Code” og “GitOps”
Bloggen er en ganske liten deployment, kun 1 pod (container) for selve wordpress. Traefik for ingress og MOCO som MySQL Operator.
MOCO er litt av grunnen til vi valgte å flytte Tech-bloggen, både Wannabe og Gathering.org bruker MySQL som database. Vi har et ønske om å bygge de mest kritiske tjenestene våre redudant og et steg på veien er å teste ut MySQL Clustering i Kubernetes.
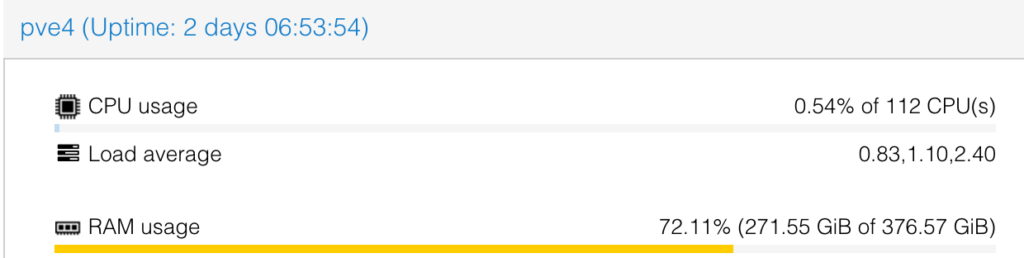
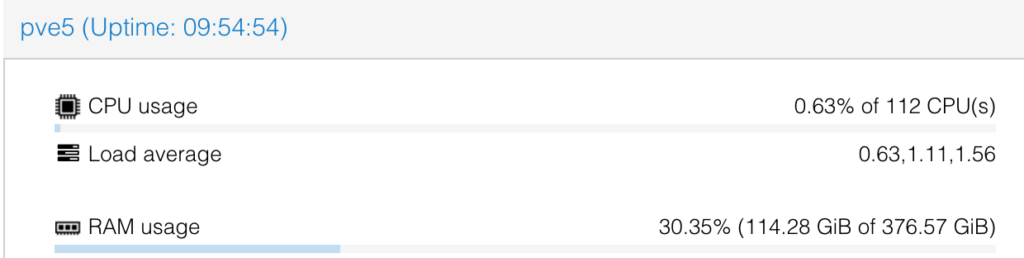
Takk til Nextron for nye servere til vårt driftsmiljø <3
2 nye servere; hver med 384 GB ram og 2 stk Intel Xeon Gold 6258R. Allerede i full sving for TG:Online. Der skal dei blant annet brukes til Minecraft, video streaming og Tech:Online.
Heisann! Selv om det ikke ble et TG21 i Vikingskipet i år, jobber vi i Systemstøtte videre med vår driftsløsning. For del 1 se The Gathering’s driftsløsninger
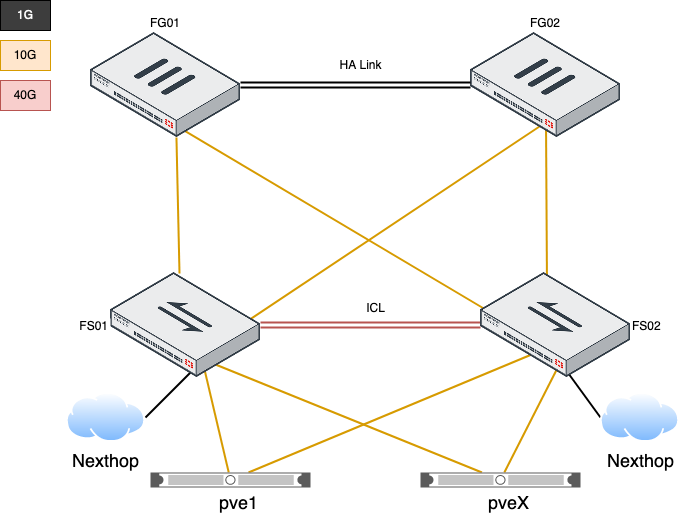
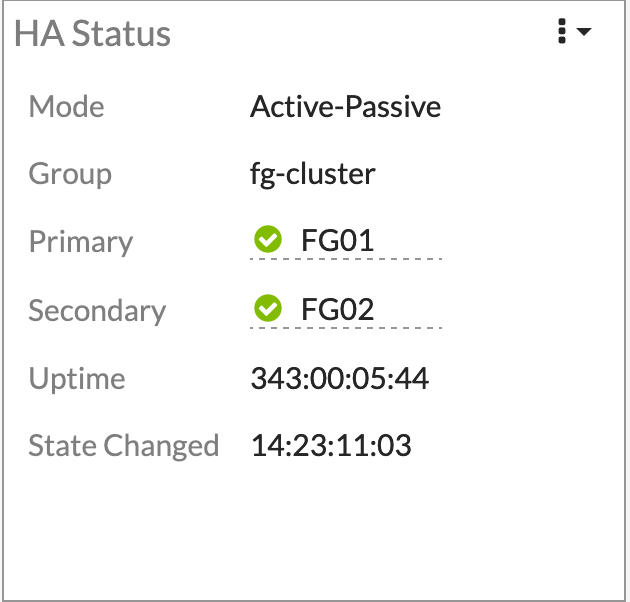
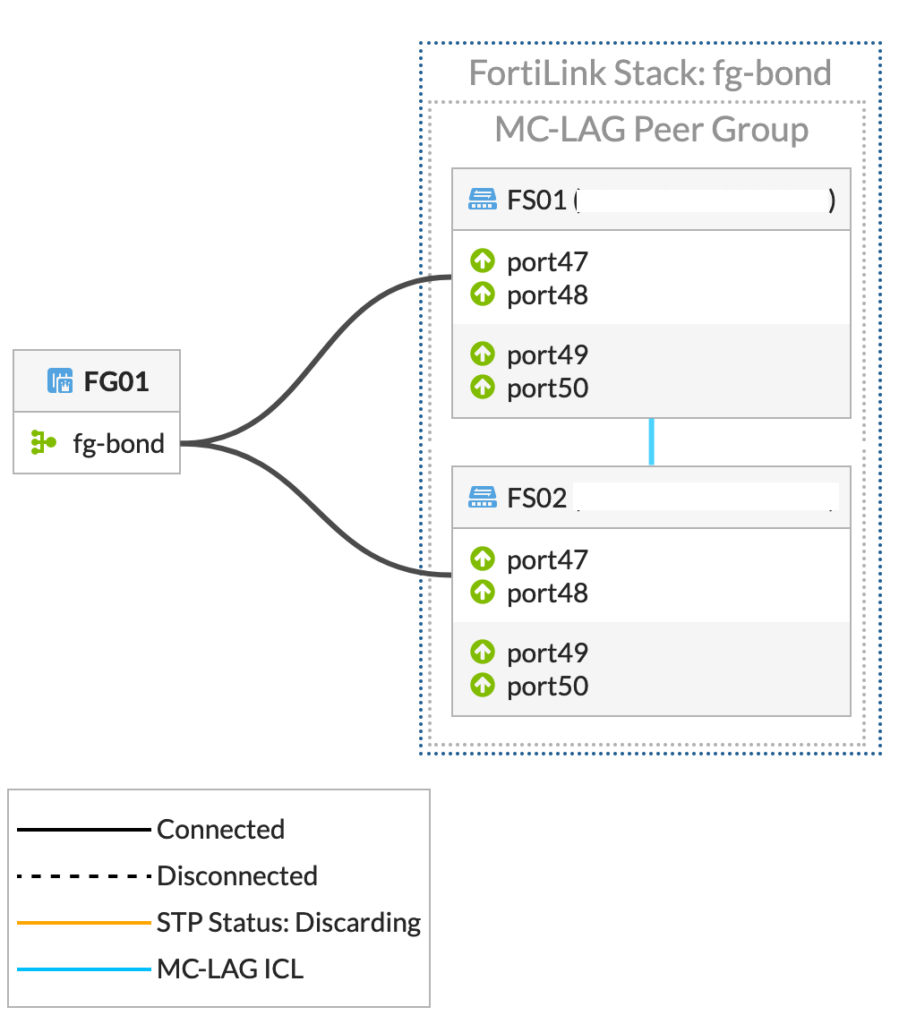
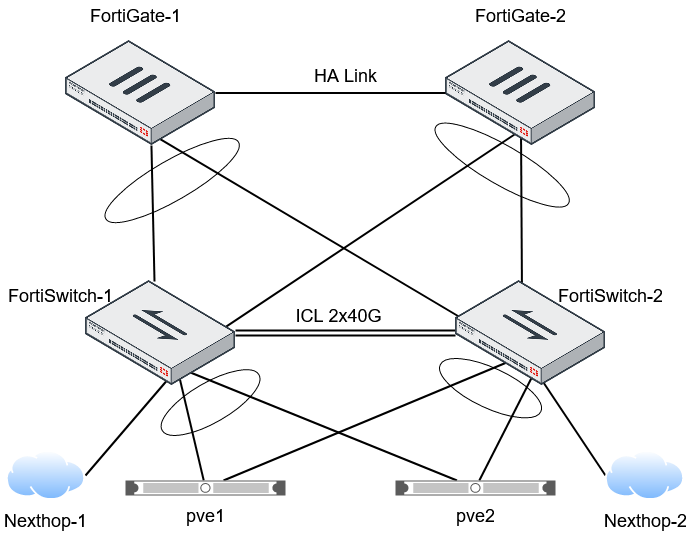
FortiGatene kjører i et Active/Passive cluster. Switchene satt opp med FortiLink. Dette gjør at vi kan styre hele nettverket fra et sted. Alt er selvfølgelig satt opp med IPv6 (og IPv4).
For å sikre redundans på switchene er de satt opp med MCLAG (Multi-Chassis Link Aggregation Group) og alle servere er koblet med minst 1 10Gbps link til hver switch (LACP). Internett fra Nexthop er koblet til begge switchene. Dette gjør at vi kan miste en FortiSwitch og en FortiGate uten at det merkes på tjenestene vi leverer. Alt har redundant strømforsyninger tilkoblet UPS og aggregat.
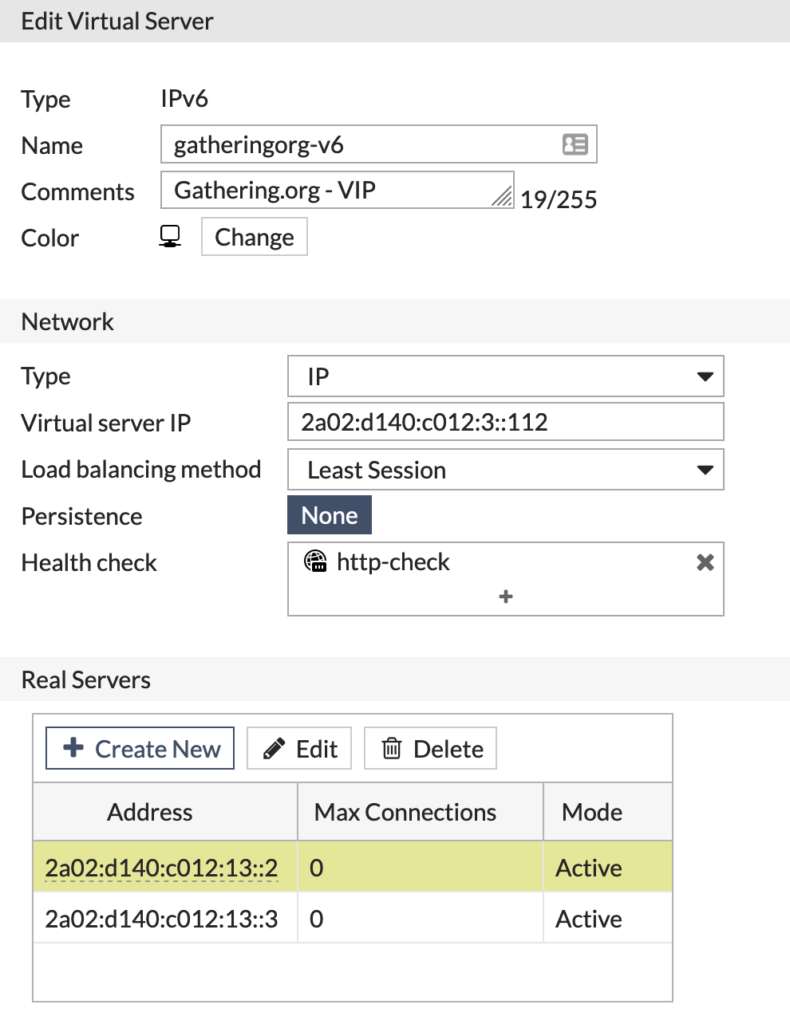
For å sikre at de mest kritiske løsningene vi har, har vi starter å leke med last balansere i FortiGate. Dette gjør at vi kan kjøre 2 eller flere servere som svarer på 1 IP adresse. Med helsesjekker blir servere som ikke svarer tatt ut av drift automatisk og tilbake når de responderer og er anset som friske.
Eksempelvis så kjører gathering.org med et slikt oppsett i dag. En “Virtual Server” som videresender trafikken til 2 servere. Dette gjør at vi i teorien kan miste en fysisk server uten at nettsiden går ned. Dessverre er vi ikke helt i mål med å få alle tjenester som kreves for nettsiden redundante. Vi snuser i tillegg på Kubernetes, men mer om det senere. De fleste tjenestene våre kjører som konteinere i Docker.
FortiAnalyzer
Vi bruker FortiAnalyzer for å følge med på trafikken som treffer nettverket vårt. Det er ikke veldig mye brukt, men alltid kult å kunne se hva som skjer ute på internett. Pluss veldig nyttig for feilsøking.
Har du spørsmål? Du finner flere av oss i #tech på TG sin Discord server. Vi snakkes!
Hvordan drifter vi egentlig gathering.org, Wannabe og alle de andre tjenestene som TG bruker?
Tenkte å blogge litt om hva vi i KANDU:Systemstøtte har drevet med den siste tiden.
Systemstøtte er i dag både en del av KANDU og et TG crew. Skillet her er for tiden litt uklart. Men det gir jo mening at de som utvikler og drifter crew systemet til TG, starter litt før de fleste andre, og tjenester som Jira trenger kjærlighet med (u)jevne mellomrom. Det innlegget her skal ikke handle om strukturen i arbeidsgruppa, men greit å være klar over at det gjøres mye også utenom The Gathering.
Vi har en stund jobbet med å fornye avtalene rundt hosting av servere, og fikk rett etter nyttår i havn en avtale med Nexthop AS for colocation. Spesifikt 20 rack units i et topp moderne datasenter i nærheten av Oslo. For en organisasjon med frivillige gjør tilgang 24 timer i døgnet ting mye lettere.
Colocation?
Colocation eller colo som det ofte kalles, er kort fortalt tilgang på datahall til å plassere servere og/eller nettverksutstyr. Leverandøren av datasenteret tar for seg drift av strøm, kjøling og annen infrastruktur. Vi fått tilgang på et «halv-rack» (20U).
1U er 4,44 cm i høyden, og standard 19 inch rack er på 48,2 cm i bredden. En vanlig server er fra 1U til 4U, spesielt om du har mye disker kan den være enda større. Les mer om colocation på nexthop.no
Nettverk
Vi har også jobbet med vår partner Fortinet for å bygge en nettverksløsning til å bruke i det nye racket. Sammen med Fortinet har vi kommet frem til en løsning som vi er veldig fornøyd med.
48x 10Gbit/s porter med blant annet 4x 100Gbit/s uplink porter.
(Med andre ord, det bør holde en stund fremover)
Under konfigurering av utstyret
Internett er levert av Nexthop over 2 redudante gigabit linker. Vi har fått et /26 nettverk med IPv4 og en /48 med IPv6. Vi kommer også tilbake med en ny bloggpost når vi hatt litt mer tid med utstyret.
Servere
Via samarbeidsavtalen vi har med Nextron på The Gathering, har vi gjennom årene fått litt servere. Målet er å flytte alt over til racket vi har hos Nexthop og vi er allerede godt i gang. Basefarm har også hjulpet oss med servere, litt utstyr og møtelokale.
Vi har mange spennende planer for driftsmiljøet fremover, og detaljene der vil helt garantert komme i en ny bloggpost etterhvert. Per nå er miljøet hos Nexthop tenkt til alt fra produksjonsmiljøer med Gathering.org og Wannabe til testing av nye løsninger og for å mette behov for hosting som crewet har før og etter selve arrangementet.
Merk at vi fremdeles kommer til å ha servere i skipet under The Gathering, dette er bare for tjenester som må kjøre utenfor TG.
Over en årrekke har Wannabe, “crew-systemet” til The Gathering, utviklet seg til å bli et ganske sindig system for å ta i mot søknader til crew, generere dataunderlag til ID-kort, holde oversikt over hvem som skal rydde når, matallergier, og en hel skog av andre funksjoner som brukes for å avvikle The Gathering hvert eneste år.
Og i nesten like mange år har folk ønsket å bruke Wannabe til andre arrangementer enn TG. Dette er noe vi har lyttet til og i en lengre tid har det vært planlagt å slippe Wannabe som Open Source slik at du selv kan ta det i bruk – og bidra tilbake.
Hovedgrunnen til at det ikke har skjedd er den vanlige: Det krever at vi går litt over koden og sjekker at det ikke er noe åpenbart idiotisk der på sikkerhetsfronten, og så må vi faktisk gjøre litt praktisk planlegging av hvordan ting skal organiseres. Ikke mye, men litt.
I hvert fall siden jeg arvet “hovedansvaret” for wannabe i slutten av 2016, og Core:Systems ble “Rebootet”, har det ligget i kortene at Wannabe sin kildekode skulle slippes.
Så hvor er den?
Vel, teknisk sett ligger den på github, men fordi det er TG om et par uker har vi bestemt oss for at den rette tiden å slippe koden ikke er akkurat nå, siden eventuelle “katastrofalt dumme bugs” vil få så store konsekvenser. Derfor annonserer vi heller at koden vil bli sluppet offentlig litt etter TG, og den datoen er satt og godkjent som: 1. Juni 2019.
I samme slengen vil vi også legge ved koden som ligger bak gathering.org, da det ikke er noen grunn til at dette skal være lukket.
Så nå har dere noe å se fram til!
Om dere har noen spørsmål, ta gjerne kontakt på discord! (å finne discord’en vår er overlatt til leseren som en ferdighetsprøve).
Om du fulgte med veldig nøye på ettermiddagen søndag 3. mars så la du kanskje merke til at www.gathering.org var utilgjengelig i en liten stund. Perioden med nedetid var varslet i god tid i forveien (ca 30 minutter) slik at alle i crewet visste hva som foregikk (her kommer altså forklaringen så alle i crewet vet hva vi gjorde).
Historien begynner med at noen små og store nerder satt samlet på Frivillighetshuset i Kolstadgata 1 i Oslo. KANDU:Systemstøtte hadde hatt møte dagen før og vi hadde blitt enige om at vi måtte gjøre noe med hvordan www.gathering.org fungerte. Før vi begynte bestod nettsiden av en server med en salig blanding av Apache, Varnish, WordPress, og vår egenutviklede Node.JS baserte web API. Konfigurasjonen var så komplisert at var lett å gjøre feil som kunne være vanskelige å nøste opp i. Vi bestemte oss derfor å bygge alt opp på nytt igjen. Dette er forklaringen på hva vi endte opp med, og en intro til hvordan det fungerer.
HTTP og HTTPS
Når du åpner en nettside med alle moderne nettlesere så benytter du en protokoll som heter Hypertext Transfer Protocol (eller bare HTTP). Protokollen håndterer å hente og sende informasjon til nettsider på en standardisert måte. Du har sikkert lagt merke til at foran de fleste linker så står det noe lignende http://example.com. Dette er en instruks for nettleseren om å prøve å nå example.com over http protokollen.
Det eneste problemet med protokollen er at alt du sender over den er fullt leselig for alle som lytter. Noen glupe hoder fant ut at om du legger til en S på slutten av HTTP så får du HTTPS, og “S”en står for “Secure”. Når nettleseren prøver å nå serveren så blir de enige om en felles krypteringsnøkkel slik at de kan kommunisere med hverandre uten at andre kan se hva som blir sendt. Metoden heter Diffie-Hellman key exchange (DH) og du kan lese mer om den her.
Før vi bygget om stacken vår så var det Apache som hadde ansvaret for å ta imot HTTPS tilkoplinger, men det var lett å lage redirect looper mellom Apache og Varnish (hvor nettleseren din blir sendt frem og tilbake mellom Apache og Varnish i all evighet) så vi valgte en annen metode. Vi installerte Hitch på serveren og konfigurerte den til å bruke et SSL/TLS sertifikat fra Let’s Encrypt. Hitch gjør ingenting annet enn å ta imot tilkoblingen, dekryptere den og sende forespørselen videre til neste ledd i prosessen.
Caching og reverse proxy
Nå som Hitch tar imot HTTPS så trenger vi å route forespørslene til riktig sted. Til det installerer vi Varnish. Varnish er egentlig en webcache, men programvaren har mange kraftige funksjoner som gjør det praktisk å bruke den som en proxy også.
Siden www.gathering.org består av to forskjellige biter i bakgrunnen trenger vi å proxye (videresende) alle forespørsler for https://www.gathering.org/api til WordPress, mens resten går til en Node.JS basert applikasjon på https://www.gathering.org/tg19. Fordelen med en reverse proxy her er at du som bruker av nettsiden bare trenger å forholde deg til en webadresse, mens webserveren som tar deg imot kan benytte mange tjenester i bakgrunnen uten at du legger merke til det.
Men hva er en cache? En cache er et mellomlager mellom deg og nettsiden som gjør responsen fra nettsiden raskere. Når du kobler til en webside så må webserveren generere en versjon av nettsiden for deg. Dette kan være en tung oppgave og kan ofte være treg. Det cachen gjør er å ta vare på en kopi av nettsiden, så når neste person spør om samme nettside så svarer Varnish bare med den mellomlagrede kopien istedenfor å la webserveren generere en helt ny en. Dette fungerer bare en liten stund, for etterhvert så endrer jo innholdet på nettsiden seg når det blir publisert nye artikler og slikt, så Varnish kan bare mellomlagre sider i maksimalt noen minutter. Kanskje bare så lite som noen sekunder hvis innholdet endrer seg fort. I www.gathering.org sitt tilfelle så lagrer vi dataen ganske lenge for vi har satt det opp slik at dersom noe innhold endrer seg så sendes det en beskjed til Varnish om å slette den mellomlagrede kopien.
Hva skjer etterpå?
Nå som forespørselen er kommet gjennom Hitch og Varnish så ender den enten opp direkte i vår Node.JS applikasjon eller så treffer den Apache som leverer WordPress siden. Totalt sett så ser arkitekturen vår slik ut.
Hvordan vi bruker WordPress og vår egenlagde frontend kommer vi nok tilbake til i en senere bloggpost (og kanskje kan du få tatt en titt på koden?).
Jeg vekket akkurat contrib.gathering.org til live, men dette blir en to-delt blog-post.
Hva er contrib.gathering.org?
La oss begynne med det viktigste: contrib.gathering.org er en samling linker til ting som er løst relatert til TG. Jeg håper lista vil eksplodere, etter hvert som alle dere der ute som lager ting får lagt til innholdet deres. Hjelp oss!
Den enkleste måten å gjøre det på er via github. Helst kan du lage en pull request, men et vanlig issue virker selvsagt også.
Vi håper å få samlet så mye artige linker (relatert til TG som mulig). Bildegallerier, konkuransebidrag, eller hva det måtte være. Bruk fantasien!
Del to: Deploy
Den andre delen av denne posten er stacken som ligger bak. Tidligere har alt vi hoster på TG stort sett ligget på den samme enorme serveren, men nylig har vi begynt å bevege oss over i litt mer moderne metoder. Contrib er foreløpig den desidert mest moderne pipelinen vi har. Den vil forhåpentligvis være et positivt bidrag for å få flyttet andre, viktigere websider over til mer moderne og fleksible utviklingsmiljøer.
Selve biten med rst2html og sånt for å generere html er ganske lite interessant.
Det som er artig er at dette kjører på Kubernetes. I dag kjører det på Google Cloud, men det kan selvsagt kjøre andre steder også – vi prøver ut Google Cloud først.
For å deploye til “prod” er alt vi trenger å gjøre i dag å comitte til master-branchen i git, når det skjer så trigges en automatisk bygg i Google Cloud, som avslutter med å gjøre en deploy i kubernetes-clusteret (også i google cloud). Denne deployen gjøres med en rolling update.
I dette tilfellet er det forholdsvis overkill, siden det ikke er noe kode bak – bare statiske filer – men det er en fin test, og vil gjenbrukes for andre prosjekter.
For de interesserte så ligger alt for deployment i samme git-repo. En rask gjennomgang:
~~~~.text
/Dockerfile – Denne brukes til å bygge en
container, den kan kjøres på din lokale laptop om du vil
/cloudbuild.yaml – Dette brukes av den automatiske
byggeprosessen. Kort fortalt definerer den at ved
en ny git commit skal det gjennomføres en docker build,
push og kubernetes deploy.
/k8s/ – Dette er ressursene som er lagt opp i Kubernetes.
De er i utgangspunktet bare lagt til en gang for hånd,
eller ved endringer.
/k8s/deploy.yaml – dette er selve deploymentfila, som i
praksis bare definerer hvilket image vi skal bruke. Imaget
oppdateres automatisk av byggescriptet.
/k8s/service.yaml – Her gjør vi deploymenten tilgjengelig for
andre tjenester i clusteret
/k8s/ingress.yaml – Denne definerer at tjenesten skal
eksponeres på internett, via “ingress”-tjenesten. Den
spesifiserer domenet, og ber om SSL-terminering, via
let’s encrypt.
~~~~
(Jadda, flott med en blog der bullet points er brukket)
Det som ikke ligger i det repoet er resten av infrastrukturen: ingress-kontrolleren og let’s encrypt automatikken. Dette kan det hende det kommer mer om når det faktisk er 100% ferdig. Teknisk sett kjører alt dette på min personlige gcloud-konto/cluster i dag…. Fordi jeg glemte igjen login/passord til KANDU/TG sin konto på jobben (… glemte “pass git push”, for de nysgjerrige).
Wannabe er et evig mysterium. En stor dinosaur med svære misfostrede armer og bein, en ekstra hale og noen store, unormale kuler. Kort fortalt så er Wannabe TGs “management-system” for frivillige.
Wannabe?
De fleste kjenner nok Wannabe som det systemet der man søker seg inn i crewet på TG. Fyller ut side opp og side ned med utrolig finskrevet og bearbeidet tekst, i håp om at man kanskje endelig kommer inn i crewet, eller i håp om at man får fortsette å være med. (misforstå meg rett her, vi trenger maange i crew). Systemet lar deg så vente, noen venter litt, andre venter lenge. Og plutselig en dag får man en slik velkomst-mail fra Wannabe om at “tjohei, kom å bli med i crew, da!”. Da har Wannabe gjort sitt for deg, tenker du. Nå er Wannabes funksjonalitet for deg bare en enkel liste over hvem du er crew-buddies med.
Men hva ANNET brukes Wannabe egentlig til?
Som du sikkert las øverst så er Wannabe en dinosaur. Og med det så menes det at på et eller annet tidspunkt ble bestemt at alt skal styres fra Wannabe. Du har naturlige funksjoner som hører til i Wannabe, som behandling av crew og søknader, utsendelse av SMS, epostliste-administrasjon, oppmøte, ernæring og medisinsk informasjon og lignende. Men så har du jo også ting som Logistikk-systemet til TG, lost and found, Akkrediterings-modul, sovekart og styring av infoskjermer.
Det betyr at: en deltaker har mistet noe, hva gjør crewmedlemmene som skal sjekke etter det? De bruker Wannabe. Når en skal dele ut akkreditering til en journalist, hva må du gjøre? Logge deg på Wannabe. Du vil oppdatere sovekartet? Logg deg på Wannabe. Få ut informasjon til deltakerene via de mange info-skjermer? Logg deg på Wannabe.
Et flott kaos..
Du må virkelig ikke misforstå meg her, fordi Wannabe er et veldig bra system, med sin egen lille sjarm. Det er bare en dinosaur. Og som alle andre dinosaurer så er de svære, vanskelig å ha med å gjøre og trøblete å ha oversikt over. Men det funker! Wannabe fungerer, gjør det det skal og bare tråler videre.
Systems sin oppgave i dette
Vi er jo Systems, og vi skal ha kontroll på dette. Vi administrerer alle modulene, oppdaterer de, vedlikeholder de og gir de den etterlengtede kjærligheten de trenger. Vi gjør også andre ting, som å gi tilganger og godkjenne profilbilder.
Wannabes fremtid
Det som er “inn” i dag er jo mikrotjenester, la frontend skrike til backend igjennom et RESTful API, som naturligvis er stateless og famler i mørket. Det er nok også dit Wannabe skal, om noen år. Segmentering av tjenestene som Wannabe tilbyr er nok en av de beste veiene å gå. En egen liten by av docker-konteinere som snakker sammen og samarbeider i harmoni for å gi brukeren det en måtte ønske. Ahh, for en flott fremtid..
Og til syvende og sist så prøver vi bare å ha system..