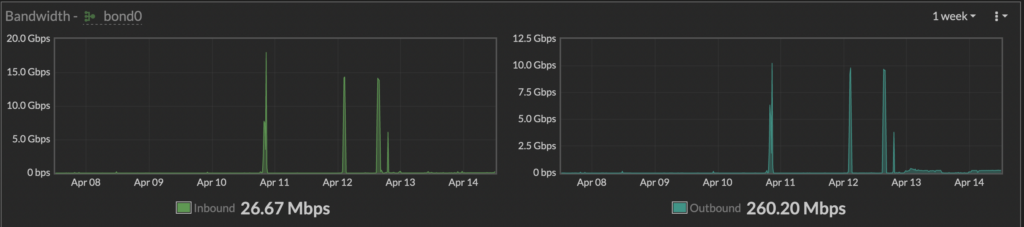
Tech er på plass i Vikingskipet og vi har internett!
Litt speedtesting
Vi kommer også til å ha en stream på TGTVCreative hvor vi skal snakke litt om dataparty og hva vi har gjort på årets arrangement. Tune in på Twitch fredag 14:30!
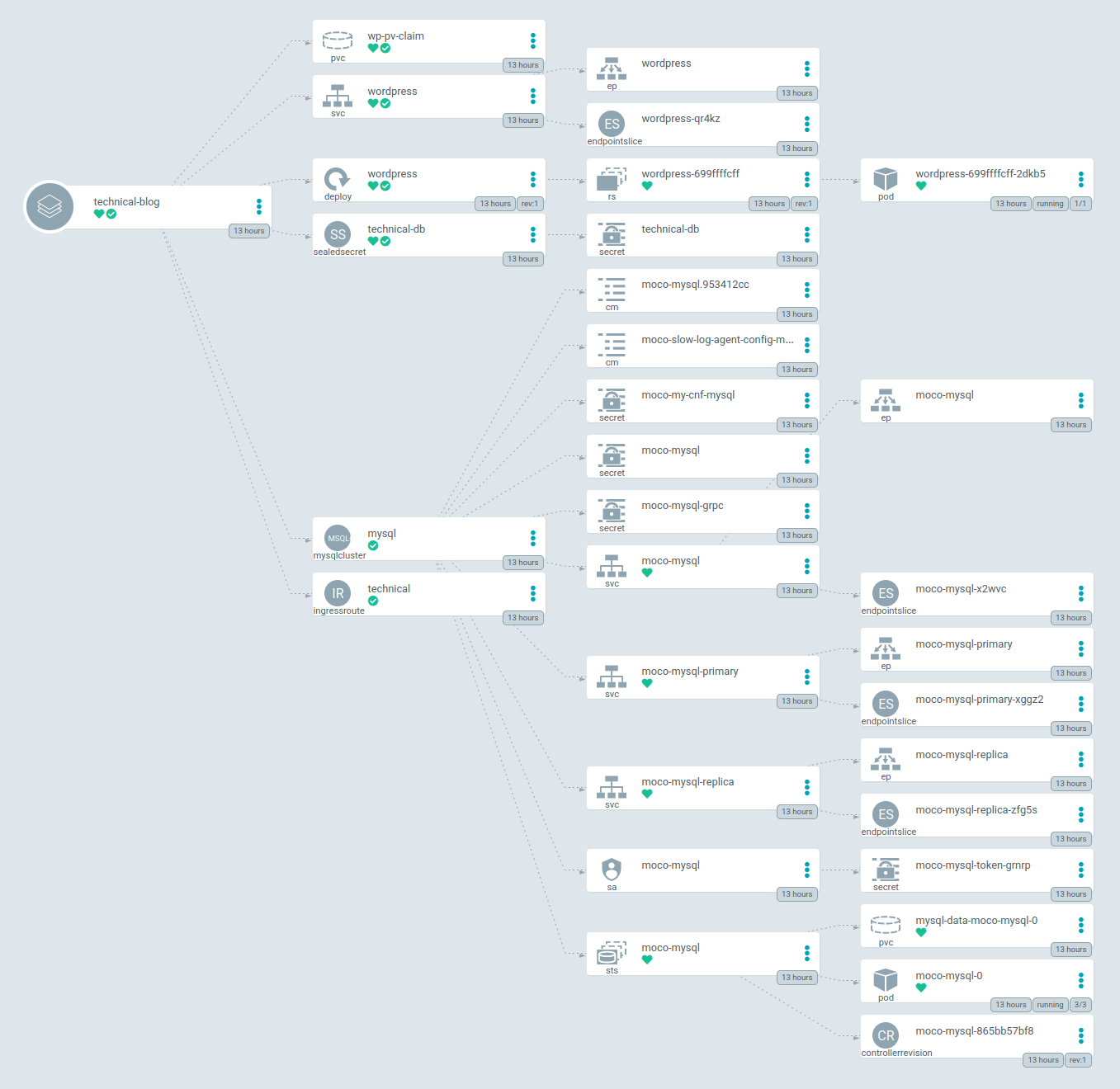
Til dere som har søkt crew til TG22 har nok merket noe nytt med Wannabe. Nettopp! Wannabe kjører i Kubernetes (og vi har darkmode!). Mer om Kubernetes og Wannabe5 må bli en annen bloggpost. Denne korte posten handler om vår blogg.
Med ny versjon av Wannabe ble det klart vi ønsket mer automatisering og DevOps. Denne bloggen ble egentlig planlagt som den første produksjons-workload i det nye clusteret. Men på grunn av litt dårlig planlegging ble Wannabe5 først. Ca 2 måneder etter vi gikk live med Wannabe ble det denne bloggen sin tur.
Vi bruker Argo CD for å få “Infrastructure as Code” og “GitOps”
Bloggen er en ganske liten deployment, kun 1 pod (container) for selve wordpress. Traefik for ingress og MOCO som MySQL Operator.
MOCO er litt av grunnen til vi valgte å flytte Tech-bloggen, både Wannabe og Gathering.org bruker MySQL som database. Vi har et ønske om å bygge de mest kritiske tjenestene våre redudant og et steg på veien er å teste ut MySQL Clustering i Kubernetes.
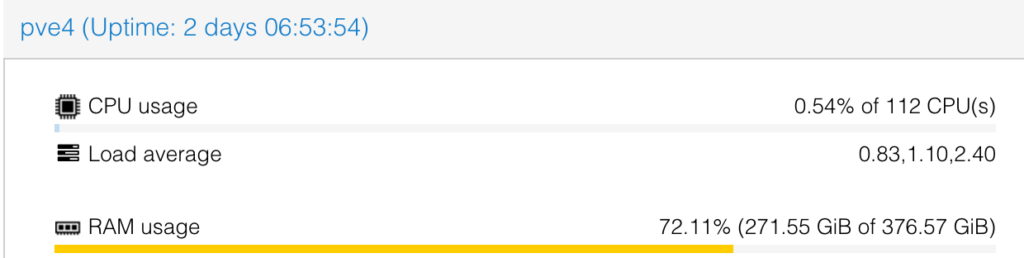
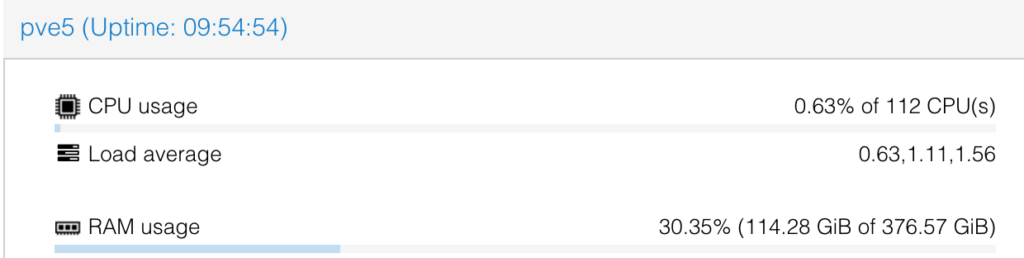
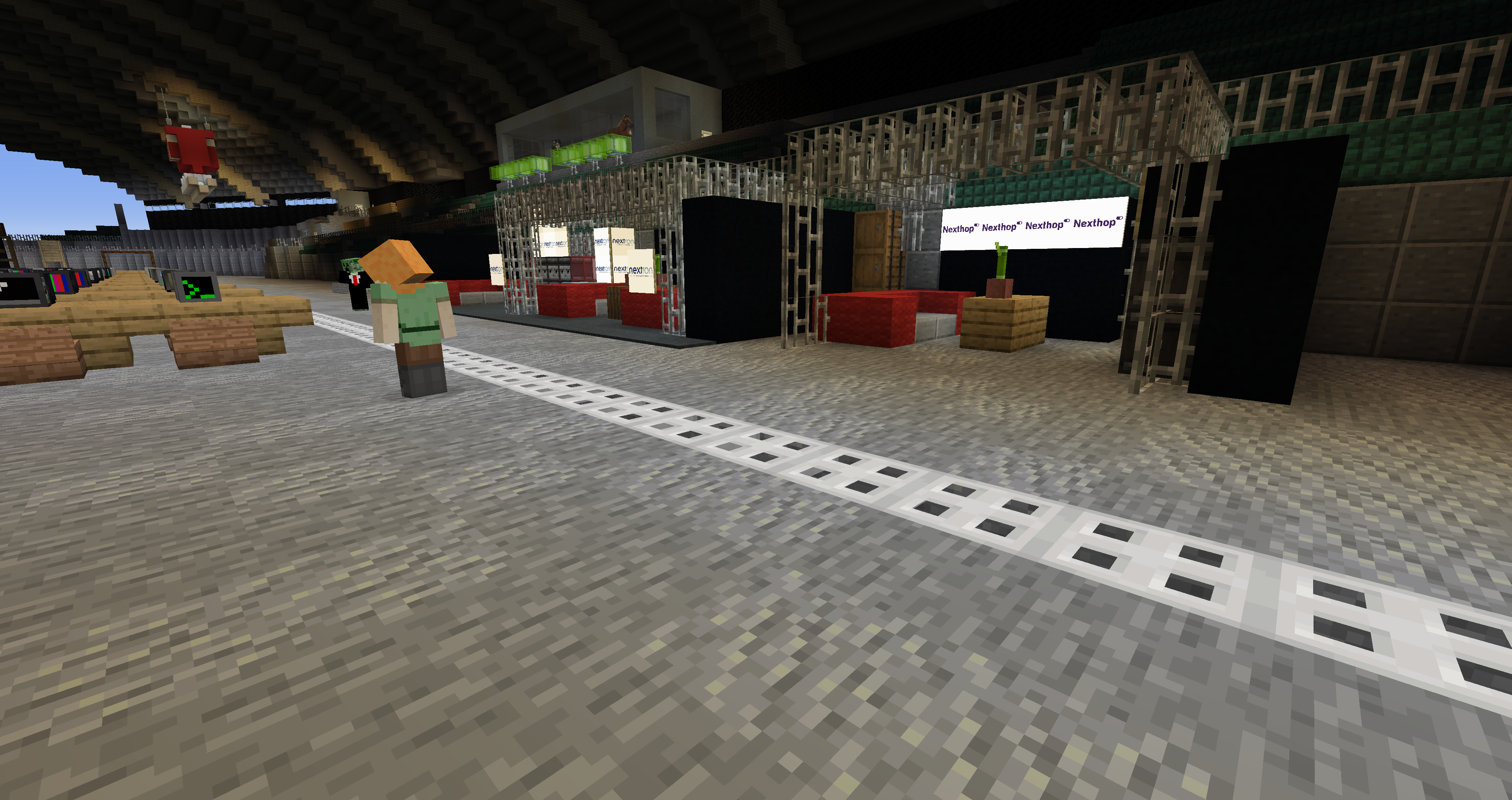
Takk til Nextron for nye servere til vårt driftsmiljø <3
2 nye servere; hver med 384 GB ram og 2 stk Intel Xeon Gold 6258R. Allerede i full sving for TG:Online. Der skal dei blant annet brukes til Minecraft, video streaming og Tech:Online.
Heisann! Selv om det ikke ble et TG21 i Vikingskipet i år, jobber vi i Systemstøtte videre med vår driftsløsning. For del 1 se The Gathering’s driftsløsninger
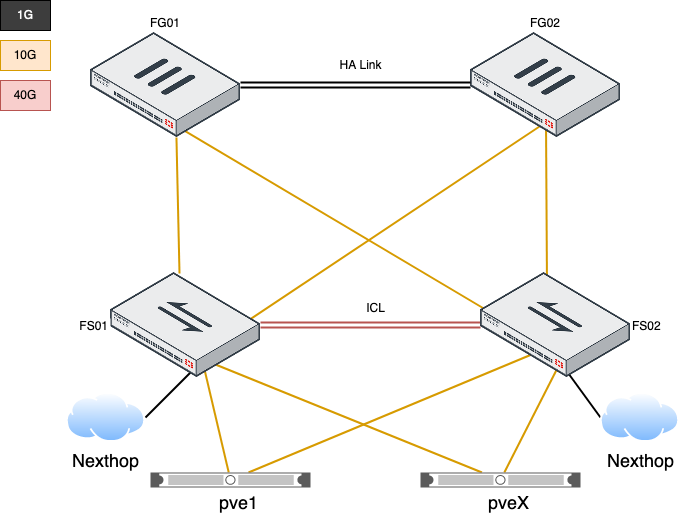
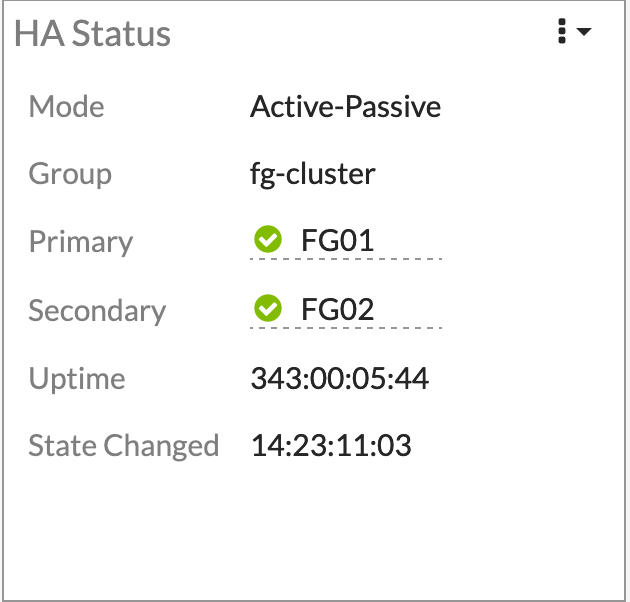
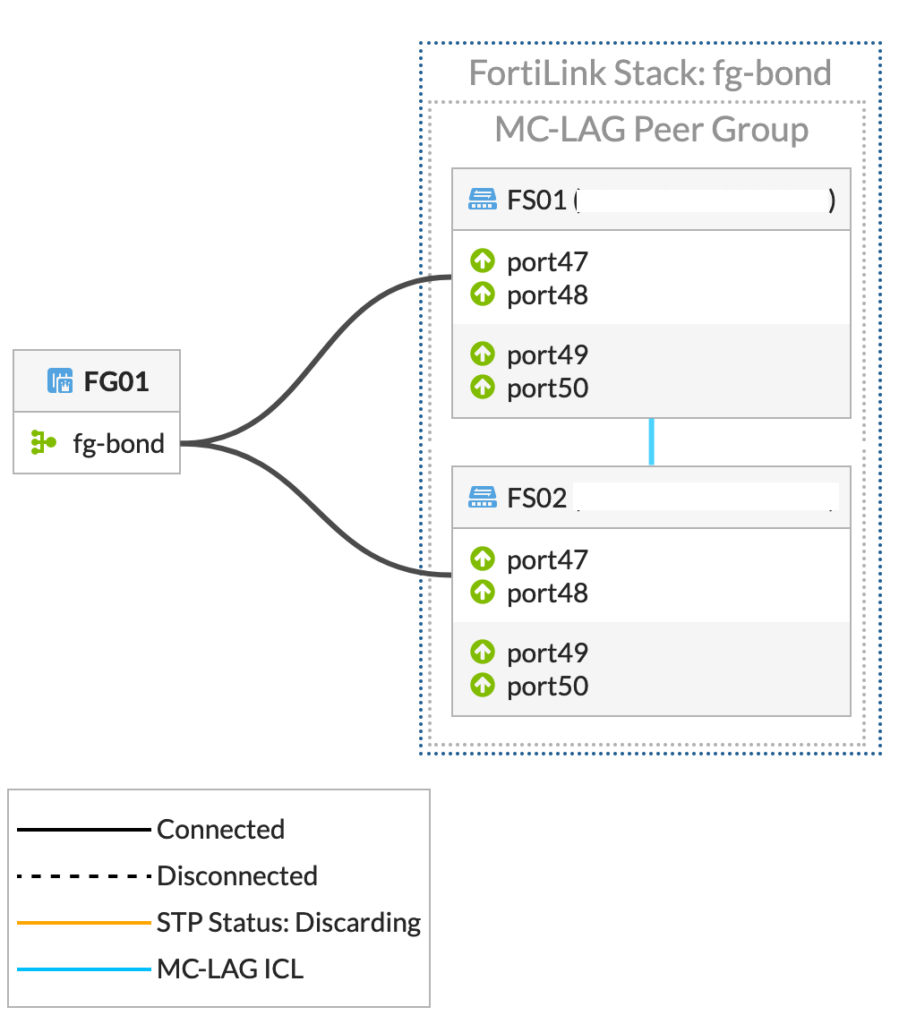
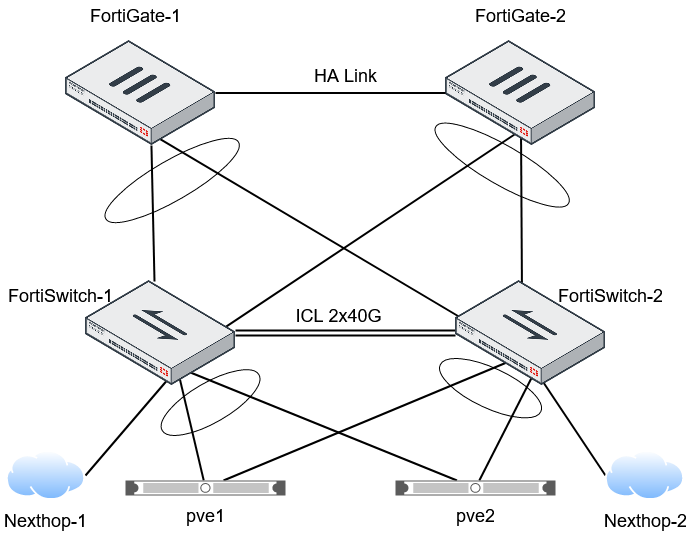
FortiGatene kjører i et Active/Passive cluster. Switchene satt opp med FortiLink. Dette gjør at vi kan styre hele nettverket fra et sted. Alt er selvfølgelig satt opp med IPv6 (og IPv4).
For å sikre redundans på switchene er de satt opp med MCLAG (Multi-Chassis Link Aggregation Group) og alle servere er koblet med minst 1 10Gbps link til hver switch (LACP). Internett fra Nexthop er koblet til begge switchene. Dette gjør at vi kan miste en FortiSwitch og en FortiGate uten at det merkes på tjenestene vi leverer. Alt har redundant strømforsyninger tilkoblet UPS og aggregat.
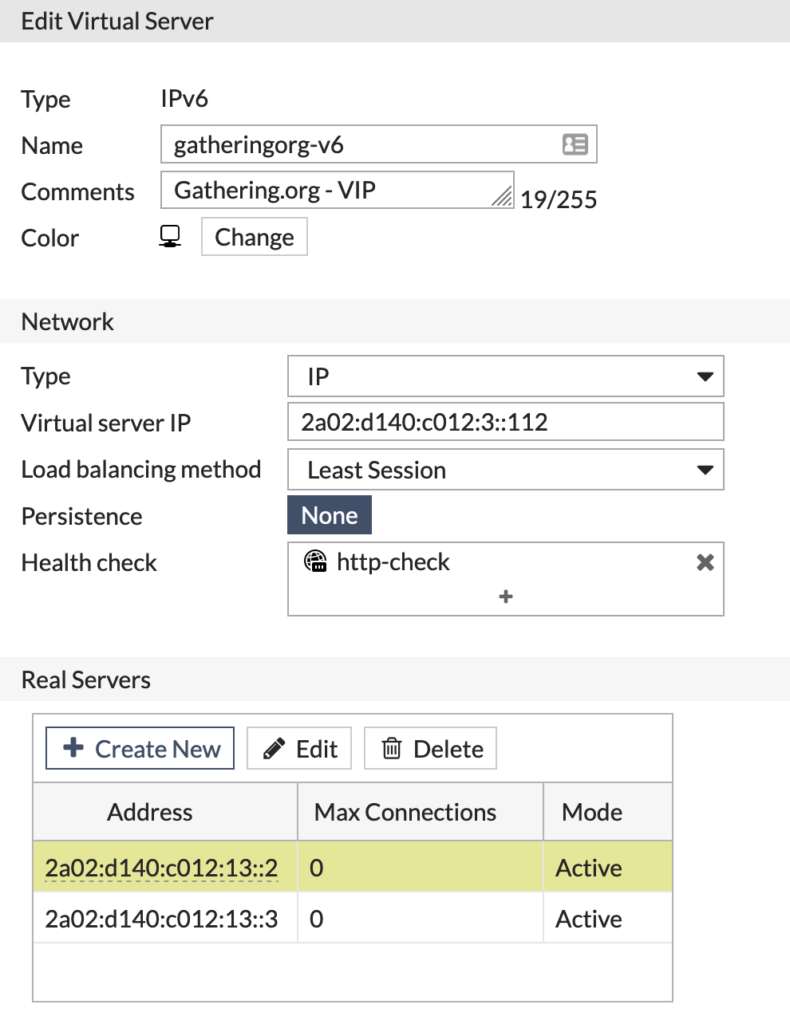
For å sikre at de mest kritiske løsningene vi har, har vi starter å leke med last balansere i FortiGate. Dette gjør at vi kan kjøre 2 eller flere servere som svarer på 1 IP adresse. Med helsesjekker blir servere som ikke svarer tatt ut av drift automatisk og tilbake når de responderer og er anset som friske.
Eksempelvis så kjører gathering.org med et slikt oppsett i dag. En “Virtual Server” som videresender trafikken til 2 servere. Dette gjør at vi i teorien kan miste en fysisk server uten at nettsiden går ned. Dessverre er vi ikke helt i mål med å få alle tjenester som kreves for nettsiden redundante. Vi snuser i tillegg på Kubernetes, men mer om det senere. De fleste tjenestene våre kjører som konteinere i Docker.
FortiAnalyzer
Vi bruker FortiAnalyzer for å følge med på trafikken som treffer nettverket vårt. Det er ikke veldig mye brukt, men alltid kult å kunne se hva som skjer ute på internett. Pluss veldig nyttig for feilsøking.
Har du spørsmål? Du finner flere av oss i #tech på TG sin Discord server. Vi snakkes!
Dei fleste fekk vel med seg avlysinga av The Gathering 2020, som da opna eit prosjekt for å dempe TG-abstinensane frå både crew og deltakarar, nemleg TG:Online. TG:Online bestod då av litt konkurransar, mykje streaming, litt stemning på discord og ein tøff Minecraft server, som me skal fordjupe oss i her!
Det starta med at eg kom med eit forslag til den interne ide-gruppa til TG:Online den 17 mars, som lød slik:
Den stjerna skal eigentlig blinke gul og raud
Som da trigga ein del respons. Sjølv om forslaget mitt då var halvveis på kødd, viste det seg at samtlege crewmedlemmar var gira, og at Nextron, so gode som dei er, kunne stille opp med hardware til prosjektet. 12 dagar etter forslaget starta det første møtet der me drøfta korleis prosjektet skulle sjå ut, deretter hadde me to veker til det blei live, og slik blei det:
Hardware
Vi hadde alt ein bestilling på diverse serverar som blei bygd i forkant av avlysinga, som Nextron var gira på å låne vekk til TG:Online i staden for. Me fekk da 2(!) av desse specsa:
2x Intel Xeon Platinum 8280L – 28-Core 2.7Ghz Base 4Ghz Turbo 512GB RAM 2x 256GB M.2 SSD i RAID-1 (boot) 6x 480GB SATA SSD 2x10GbE SFP+
Det er gøy.
Men kor skal vi ha serveren? Vanligvis har me jo alle maskinene våre i vikingskipet, men ettersom den planen gjekk vestover måtte vi går til ein av KANDU sine samarbeidspartnere, nemleg colocation hos Nexthop! Der har me og ein Fortigare brannmur som fort kan komme til nytte! Tidlegare har Ole Mathias posta bilete frå installasjonen av serverane
Software
I beskrivelsa av software til prosjektet snakkar me om alt av rein software som gjorde prosjektet mogleg, og startar kronologisk med det som er i botnen.
For i botnen starta me med Proxmox til kvar av serverane. Proxmox har blitt veldig populært inna TG sitt tech-miljø, og har opna for lett skalering, IPA, flytting av VM utan downtime med meir, so det var eit sjølvfølgje for oss!
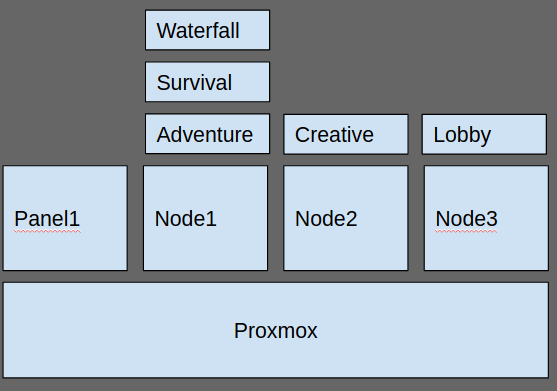
Deretter kjem game sin favoritt, nemleg pterodactyl! Pterodactyl opnar da for veldig lett administering av docker containers av spel, deriblant forskjellige variantar av Minecraft serverar. Det har eit kult API, kjapp deployment muligheit for serverar, brukaradministrering av serverar, tilgang til filsystem og CLI til containerar, administrering av database og mykje meir!
Eksempel oppsett, her er alle “likesida” firkantane VM’ar, og dei avlange er Minecraft server instancesi eigne docker containers
Deretter går me til det som er sjølve Minecraft serverane, og det har kanskje behov for ein liten forklaring.
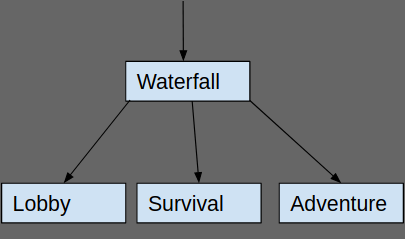
“Vanleg” Minecraft køyrar java som dei fleste veit. Grunna det pluss Minecraft sin utvikling dei siste ti åra brukar Minecraft server instansen hovudsakleg kun ein CPU kjerne, som gjer da eit 56 core beist som me har litt ubrukeleg dersom me skulle berre hatt ein server instance. Difor gjor me som det fleire andre større serverar, nemleg å ha eit proxy oppsett. Det fungerar med at me har ein proxy, som bungeecord eller waterfall, som då i klienten sine auge ser ut som ein heilt vanleg Minecraft server. Om klienten prøvar å kople seg til proxyen, vil den då bli sendt til eit av serverane under proxyen. Proxyen lagar og ein bru for å kople seg mellom serverar, og kan bli konfigurert til å gjer mykje gøy!
Eksempel på proxy blokkdiagram, der waterfall er ein proxy server
Der har me valt å bruke waterfall som proxy server, som då er ein fork av bungeecord, og Tuinity som Minecraft server, som er ein fork av PaperMC, som er ein fork av Spigot. Phew. Me valgte da waterfall og tuinity rett og slett for at internettet sa dei skulle gi betre ytelse, noko som me tenkte me sårt trengte då CPU’en vår ikkje har like god single-core ytelse som dei fleste profesjonelle Minecraft serverar har. Med Tuinity arbeida me internt for å få best mogleg ytelse og optimalisering, og me var veldig bleeding edge med Tuinity verisjonen me køyrde i produksjon.
Litt anna som er verdt å nemne er at me konfigurerte ein close-to autodeploy av forskjellige Minecraft server instances, som gjer at dersom det hadde komt hundrevis, eller tusenvis av folk, kunne vi kjapt skalere opp anntalet survival, creative og lobby instances.
Plugins
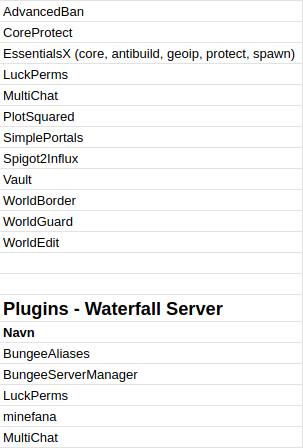
Plugins på Minecraft er essensielle for å drive ein større server. Det kan ver plugins for å administrere moderering og banning på tvers av serverar, plugins for å stenge av spawn område, plugins for å lage portalar mellom server instances, osv osv. Naturligvis har me og behov for nokon plugins.
Plugins me brukte, der dei øverste er for server instances mens dei nedenfor er for proxy server
Me skal ikkje gå inn på alle plugins, ettersom der er mange småting som blei konfigurert. Men vi skal gå inn på det mest spennande!
LuckPerms er nok den viktigaste pluginen me hadde i sin heilheit, då det den gjorde var å passe på server rollar på tvers av instances. Dvs om man har moderator rolle på lobby, har man og moderator rolle på adventure server. Me hadde behov for ein felles database for den pluginen som alle serverane snakka til.
Ein anan plugin som krev database er CoreProtect, som loggar alt av aktivitet på kvar server, har rollback muligheit og mykje meir. Kontra LuckPerms krev den ein database per server, dog.
WorldGuard vart kun brukt på Minecraft Creative konkurranse server instancen, då der ikkje var behov for den andre plassar. WorldBorder blei brukt for å førehandsgenerere survival verdenane våre, som gjer me sparar mykje resursar på generering i produksjon.
Tall
Her kjem det som er gøy!
For vi rakk nemleg å bli ferdig med alt akkurat før tida, og hadde ein opplevelse som gjekk over forventningane når det kom til trøbbel!
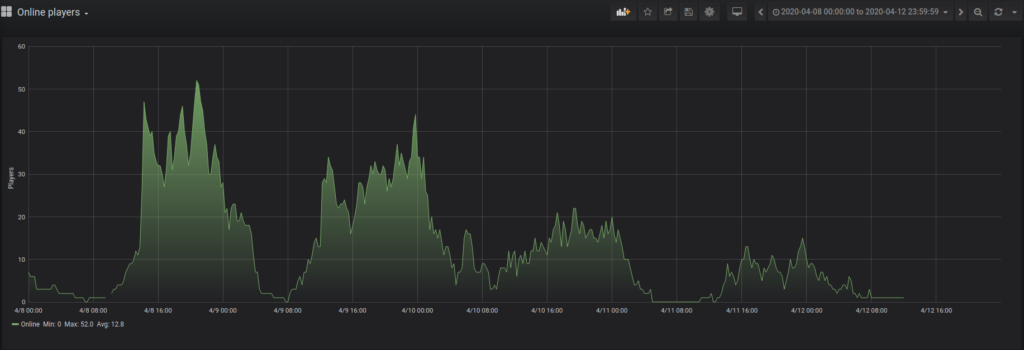
Totalt var der 384 unike brukarar som besøkte serveren vår, med ein peak på 54 spelarar som var på serveren samstundes. TPS på alle instances var på 20 (det er perfekt) heile tida, utanom når folk lagde TPS-bombs med vilje. Men det blei kjapt rydda opp i.
Me hadde og ein testdag for å sjekke kor mykje ein server instance taklar med alle pluginsa me planla å bruke, på software oppsettet me tenkte å bruke. Då fekk me nær 50 brukarar som spelte samstundes, med ein TPS på 20, og CPU core load på 30%.
Anntal spelarar per tid
Eg vil gi ein stor takk til Christian Relling og Ole Mathias Aarseth Heggem for å bruke insane med innsats på å løyse plugins og det tekniske rundt prosjektet, og eg vil og takke alle byggarane, moderatorane, og støttespelarane rundt prosjektet som gjor at barn og unge fekk game litt samla i påska i år også <3
Da var Tech:Online avholdt. Det hele startet som en litt søkt idé, men vi fikk nærmere 30 påmeldte, cirka 20 fullførte. Vi fikk rett og slett ikke tid til alle!
Hele greia gikk ut på et enkelt konsept: Du som deltaker skulle konfigurere to deltakersvitsjer og en distroswitch så en simulert deltaker/klient kom seg på nett. Dette gjorde deltakerne (vanskelig å holde hvilke deltakere vi snakker om fra hverandre nå) på ekte hardware, ved hjelp av en raspberry pi som hadde 4 konsollkabler, en til hver av svitsjene involvert. Den simulerte deltakeren – la oss kalle det klienten – var en annen raspberry pi med statisk IP-addresse og en skjerm som lyste rødt for offline og grønt for online.
Det så cirka slik ut.
Tech:Online, med tre av fire stasjoner “i mål”.
I forkant av konkurransen holdt jeg to forskjellige stream sessions/foredrag/kall-det-hva-du-vil, med litt forskjellig fokus.
Alt i alt er jeg mektig imponert over hvor dyktig deltakerne var. Vi ble lovet tre billetter vi kunne dele ut, og det ble ikke lett. For det første måtte vi bruke mye skjønn: Det å sammenligne hvem som var raskest var veldig vanskelig, både fordi vi ikke egentlig hadde noen “stoppeklokke”, og fordi de som var først ut fikk en del forsinkelser som var utenfor deres kontroll. Med det sagt så lå fullføringstiden på mellom 1:30 (en time og tretti minutter) og 5:00. Jeg er mektig imponert over begge to: Selv om ting var godt dokumentert, var det flere mindre avvik fra dokumentasjonen, og uansett er dette ikke noe folk er vant til. Og det å holde ut i fem timer, og på toppen av alt be om en runde til etterpå for å se om man har lært, det fortjener ros.
Hvilket bringer oss til…
Vinnere!
Det er kåret tre vinnere, jeg går ut med “display navn” jeg, siden vi aldri formelt spurte om samtykke til noe mer (tid, og alt det der). De er:
- CafSneak
- ent3r
- Total_Ecl1ps3
De har alle tre vunnet hver sin billett til TG21! Delvis var dette basert på at de har utmerket seg, og delvis ble det trukket.
Alle som har deltatt og fullført har uansett grunn til å være fornøyd, godt jobba!
Bak kulissene
I skrivende stund slipper jeg koden som gjorde det mulig. Dette er rett og slett selve symbolet på det jeg vil kalle “hacking” i ordets opprinnelige forstand.
Det er MYE rariteter der, og det er ganske usminket. Les README.rst og “don’t try this at home”. Men et par ting vi har lært:
Vi burde hatt mer tid til å ettergå kabling og dokumentasjon før arrangementet. Dette visste vi egentlig i forkant, men tid er en begrenset ressurs.
Dokumentasjonen skulle vært RST hele tiden. Den ble konvertert til html i en one-off jobb, som gjorde at terskelen for quick-fixes ble for høy.
Det å jobb med en ekstrem tidsfrist er faktisk gøy! Da kan du ta snarveier du ellers ikke ville vurdert.
Vi skulle hat booking av tidsfrister og signup klar mye tidligere. Vi forutså rett og slett ikke at det ble så mange påmeldte, og vi visste ikke hvor lang tid folk kom til å bruke.
Bling betyr noe! Både det at nettsiden ble stylet fint og at det visuelle var litt pynta på var viktig.
Det blir en neste gang, men vi vet ikke når eller hvor eller hvordan!
Da ble TG avlyst i disse COVID-19-tider. Nok er sagt om det, men mye var alt satt i bevegelse. Mange arbeidsdager er lagt ned i det.
Og vi (TG-crewet) prøver å stable på bena et alternativt arrangement i hurten og sturten, TG:Online. Hva dette vil være vet vi ikke helt enda, men det er uansett klart at Tech sin rolle vil være svært begrenset når vi ikke lenger skal levere nettverk og internett til 5000 mennesker.
Så jeg begynte å lure litt på hva vi kan gjøre?
En av tankene jeg har hatt er at vi har en masse nettverksutstyr vi ikke får brukt til noe. Jeg hadde selv behov for å labbe, så tok med meg litt stash hjem og så hva jeg fikk til.
Stue-lab, med “kant”, “distro” og “core”.
Så jeg leker litt med tanken på om vi klarer å levere noe sånt for flere? Vi har jo et tredvetalls konsoll-kabler og masse skjermer og NUCer på lager.
Man kan labbe virtuelt, men det har bare ikke den samme “feelingen” som fysisk utstyr har.
Hva om vi setter opp noe ala riggen på bildet, smeller konsoll-kabler på alt og lager en slags “capture the flag”-konkurranse der folk får mulighet til å konfe utstyret så pc’er kommer på nett? For å gjøre det litt gøy smeller vi på noe skjermer som “pinger” internett og litt sånt, med et webcam man kan følge med på? Gudene vet, men det høres gøy ut å prøve.
Aner ikke om det lar seg gjøre, men i mellomtiden labber jeg videre. Bli gjerne med i diskusjonen på TG sin Discord (#tech-kanalen) om dette er interessant!
Hvordan drifter vi egentlig gathering.org, Wannabe og alle de andre tjenestene som TG bruker?
Tenkte å blogge litt om hva vi i KANDU:Systemstøtte har drevet med den siste tiden.
Systemstøtte er i dag både en del av KANDU og et TG crew. Skillet her er for tiden litt uklart. Men det gir jo mening at de som utvikler og drifter crew systemet til TG, starter litt før de fleste andre, og tjenester som Jira trenger kjærlighet med (u)jevne mellomrom. Det innlegget her skal ikke handle om strukturen i arbeidsgruppa, men greit å være klar over at det gjøres mye også utenom The Gathering.
Vi har en stund jobbet med å fornye avtalene rundt hosting av servere, og fikk rett etter nyttår i havn en avtale med Nexthop AS for colocation. Spesifikt 20 rack units i et topp moderne datasenter i nærheten av Oslo. For en organisasjon med frivillige gjør tilgang 24 timer i døgnet ting mye lettere.
Colocation?
Colocation eller colo som det ofte kalles, er kort fortalt tilgang på datahall til å plassere servere og/eller nettverksutstyr. Leverandøren av datasenteret tar for seg drift av strøm, kjøling og annen infrastruktur. Vi fått tilgang på et «halv-rack» (20U).
1U er 4,44 cm i høyden, og standard 19 inch rack er på 48,2 cm i bredden. En vanlig server er fra 1U til 4U, spesielt om du har mye disker kan den være enda større. Les mer om colocation på nexthop.no
Nettverk
Vi har også jobbet med vår partner Fortinet for å bygge en nettverksløsning til å bruke i det nye racket. Sammen med Fortinet har vi kommet frem til en løsning som vi er veldig fornøyd med.
48x 10Gbit/s porter med blant annet 4x 100Gbit/s uplink porter.
(Med andre ord, det bør holde en stund fremover)
Under konfigurering av utstyret
Internett er levert av Nexthop over 2 redudante gigabit linker. Vi har fått et /26 nettverk med IPv4 og en /48 med IPv6. Vi kommer også tilbake med en ny bloggpost når vi hatt litt mer tid med utstyret.
Servere
Via samarbeidsavtalen vi har med Nextron på The Gathering, har vi gjennom årene fått litt servere. Målet er å flytte alt over til racket vi har hos Nexthop og vi er allerede godt i gang. Basefarm har også hjulpet oss med servere, litt utstyr og møtelokale.
Vi har mange spennende planer for driftsmiljøet fremover, og detaljene der vil helt garantert komme i en ny bloggpost etterhvert. Per nå er miljøet hos Nexthop tenkt til alt fra produksjonsmiljøer med Gathering.org og Wannabe til testing av nye løsninger og for å mette behov for hosting som crewet har før og etter selve arrangementet.
Merk at vi fremdeles kommer til å ha servere i skipet under The Gathering, dette er bare for tjenester som må kjøre utenfor TG.